In my previous post I made some vague comments about maximal and average error which I think are not complicated but don’t often arise when we think about plain vanilla information theory problems. These come up in arbitrarily varying channels, but also help motivate some interesting alternative models.
We most often think of error criteria as being about the desiderata for communication — asking for the maximal error over messages to be small is more stringent than asking for the average error. However, if we have a code which has small average error we can expurgate bad codewords to get a code which has small maximal error. With that meta-argument in hand, at a first pass we’re done : average error and maximal error are pretty much the same.
However, choosing an error criterion can also be a choice about the communication model. If the noise can somehow depend on what is being transmitted, then this distinction can come up. If the error criterion is maximal error and the interference is arbitrary, then for each message and each interference signal, I need to guarantee that probability of error is small. Implicitly, this allows the interference to be chosen as a function of the message. Under average error, the interference cannot be a function of the message.
If we allow for common randomness, the transmitter can mask the dependence of the codeword on the message. Suppose we have a deterministic code with  codewords which has small average error. Then we can create a randomized code by choosing a random permutation
codewords which has small average error. Then we can create a randomized code by choosing a random permutation  of and encoding message
of and encoding message  with the
with the  -th codeword of the original code. In this way we get the maximal error to be small, since the maximal error is averaged over the common randomness.
-th codeword of the original code. In this way we get the maximal error to be small, since the maximal error is averaged over the common randomness.
From this it’s clear that the choice of error criterion is also a modeling choice, especially when there is no common randomness allowed. However, this is all looking at the case where the interference can depend on the message. The trickier situation is when the interference can depend on the transmitted codeword, which is what I discussed in the previous post. In that setting using common randomness to mask the message-codeword dependence doesn’t buy that much. What I was working on recently was how much it buys you when the dependence is weakened.
As a final note, this model of interference depending on the transmitted codeword appears in a stochastic form under the name “correlated jamming” and has been worked on by several researchers, including Muriel Médard, Shabnam Shafiee, and Sennur Ulukus. My goal was to get an AVC and geometric perspective on these kinds of communication models.


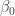 , then using Bayesian inference the posterior should concentrate around
, then using Bayesian inference the posterior should concentrate around  differential privacy on the utility functions of the users.
differential privacy on the utility functions of the users.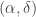 -differential privacy, but what this paper shows is that for the stricter
-differential privacy, but what this paper shows is that for the stricter  -differential privacy definition, statistical estimation is governed by the gross error sensitivity (GES) of the estimator.
-differential privacy definition, statistical estimation is governed by the gross error sensitivity (GES) of the estimator. , the feature
, the feature 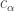 to compute and there is a total budget for the computation. The main approach is to minimize a linear combination of the loss and the cost iteratively, where each iteration consists of building a regression tree.
to compute and there is a total budget for the computation. The main approach is to minimize a linear combination of the loss and the cost iteratively, where each iteration consists of building a regression tree. nodes in a network has a change point
nodes in a network has a change point 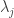 . Data is observed on vertices and edges and nodes have to pass messages on the graph. There’s a prior distribution on the change point times and after observing the data the nodes can use message passing to do some belief propagation to estimate the posterior distribution and define a stopping time. This turns out to be asymptotically optimal, in that the expected delay in detecting the change point is achieved.
. Data is observed on vertices and edges and nodes have to pass messages on the graph. There’s a prior distribution on the change point times and after observing the data the nodes can use message passing to do some belief propagation to estimate the posterior distribution and define a stopping time. This turns out to be asymptotically optimal, in that the expected delay in detecting the change point is achieved.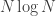 , where $N$ is the number of items (e.g. movies). It’s worse if the users are sparse — the scaling is with
, where $N$ is the number of items (e.g. movies). It’s worse if the users are sparse — the scaling is with  , which is also achievable in some settings. The analysis approach using Fano is analogous to the “information leakage” connections with differential privacy.
, which is also achievable in some settings. The analysis approach using Fano is analogous to the “information leakage” connections with differential privacy.
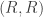 , if the first (resp. second) defects (D) they are
, if the first (resp. second) defects (D) they are 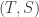 (resp.
(resp. 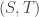 ) and if they both defect then
) and if they both defect then 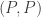 . The usual conditions are
. The usual conditions are  to keep it interesting.
to keep it interesting.