I saw this paper on ArXiV a while back and figured it would be a fun read, and it was. Post-ISIT blogging may have to wait for another day or two.
Finding a most biased coin with fewest flips
Karthekeyan Chandrasekaran, Richard Karp
arXiv:1202.3639 [cs.DS]
The setup of the problem is that you have  coins with biases
coins with biases ![\{p_i : i \in [n]\}](https://s0.wp.com/latex.php?latex=%5C%7Bp_i+%3A+i+%5Cin+%5Bn%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002) . For some given
. For some given ![p \in [\epsilon,1-\epsilon]](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B%5Cepsilon%2C1-%5Cepsilon%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and 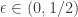 , each coin is “heavy” (
, each coin is “heavy” (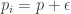 ) with probability
) with probability  and “light” (
and “light” (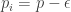 ) with probability
) with probability 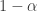 . The goal is to use a sequential flipping strategy to find a heavy coin with probability at least
. The goal is to use a sequential flipping strategy to find a heavy coin with probability at least  .
.
Any such procedure has three components, really. First, you have to keep track of some statistics for each coin  . On the basis of that, you need a rule to pick which coin to flip. Finally, you need a stopping criterion.
. On the basis of that, you need a rule to pick which coin to flip. Finally, you need a stopping criterion.
The algorithm they propose is a simple likelihood-based scheme. If I have flipped a particular coin a bunch of times and gotten 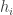 heads and
heads and  tails, then the likelihood ratio is
tails, then the likelihood ratio is
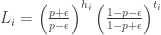
So what the algorithm does is keep track of these likelihoods for the coins that it has flipped so far. But what coin to pick? It is greedy and chooses a coin which has the largest likelihood 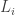 so far (breaking ties arbitrarily).
so far (breaking ties arbitrarily).
Note that up to now the prior probability of a coin being heavy has not been used at all, nor has the failure probability  . These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which
. These appear in the stopping criterion. The algorithm keeps flipping coins until there exists at least one $i$ for which
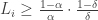
It then outputs the coin with the largest likelihood. It’s a pretty quick calculation to see that given  heads and tails for a coin $i$,
heads and tails for a coin $i$,
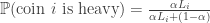 ,
,
from which the threshold condition follows.
This is a simple-sounding procedure, but to analyze it they make a connection to something called a “multitoken Markov game” which models the corresponding mutli-armed bandit problem. What they show is that for the simpler case given by this problem, the corresponding algorithm is, in fact optimal in the sense that it makes the minimum expected number of flips:
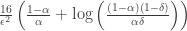
The interesting thing here is that the prior distribution on the heavy/lightness plays a pretty crucial role here in designing the algorithm. part of the explore-exploit tradeoff in bandit problems is the issue of hedging against uncertainty in the distribution of payoffs — if instead you have a good handle on what to expect in terms of how the payoffs of the arms should vary, you get a much more tractable problem.
 (plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve
(plus lower-order terms), since that is the maximum possible expected hitting time for a random walk on an n-vertex graph [2]; the same bound applies to the random cop [4]. It is easy to see that the greedy cop who merely moves toward the drunk at every step can achieve  ; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time
; in fact, we will show that the greedy cop cannot in general do better. Our smart cop, however, gets her man in expected time 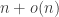 .
.
 -user interference channel with gains
-user interference channel with gains  between transmitter
between transmitter  . Then if
. Then if