Hey, lookit! I’m blogging about a conference somewhat near to when the conference happened!
I’m just going to write about a few talks. This is mostly because I ended up not taking as many notes this year, but also because writing up extensive notes on talks is a bit too time consuming. I found the talks by Paul Cuff, Sriram Vishwanath, Raj Rajagopalan, and others interesting, but no notes. And of course I enjoyed the talks by my “bosses” at UCSD, Alon Orlitsky and Tara Javidi. That’s me being honest, not me trying to earn brownie points (really!)
So here were 5 talks which I thought were interesting and I took some notes.
Bayesian Updating, Evolutionary Dynamics and Relative Entropy
Cosma Shalizi
This was the first talk of the day, which may have been a scheduling calculation, since Cosma had never been to Allerton before (you’re in a flat featureless land full of straight unmarked roads, all alike). The purpose of this talk was to try and justify why Bayesian methods work (e.g. without appeals to religion). Essentially they work by being adaptive or evolving, so he wanted to give an interpretation in terms of an “evolutionary search based on relative entropy.” More specifically, the objective is to handle mis-specification and dependence. The key aspects of the set-up is that there is a distribution 
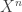
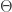



Divergence-Based Characterization of Fundamental Limitations of Adaptive Dynamical Systems
Max Raginsky
Max looked at a problem of system identification (more or less) when that system is also being controlled. Controlling a system may make it harder to identify — those special little features which make it unique and special are crushed by the control, rendering the output gray and bland and informationless. Perhaps I exaggerate. In any case, Max went on to show a minimax lower bound on the estimation error by showing that system ID is as hard as hypothesis testing (a similar approach to Yang and Barron, I think). He talked about three kinds of information in the problem — a priori information about the system, measured in terms of metric entropy, a posteriori information from the output, which is the system ID problem, and acquired (no fancy Latin) information, which turns out to be the mutual information. A cartoon version of the result is that (metric entropy) x (prob. of system ID) <= (acquired info.) + log 2.
The Impact of Constellation Cardinality on Gaussian Channel Capacity
Yihong Wu and Sergio Verdú
This was an interesting twist on the AWGN channel. Suppose I insist that you use an input distribution on a set of 
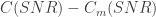

Scaling Laws for Learning High-Dimensional Markov Forests
Vincent Tan, Anima Anandkumar, and Alan Willsky
This paper was on learning the edges in a graphical model (GM) from data when the number of samples is less than the dimension of the data. The problem here is that insisting that your GM be a tree may result in overfitting. One way out is to reduce or prune out edges which have a small mutual information or correlation between the variables. This will result in learning a forest (a collection of trees) rather than a single tree containing all the nodes. They propose a variant of the Chow-Liu algorithm (as Vincent joked, “unimaginatively named CL-Thresholding”) which does this pruning and prove that it converges. There were also more general results on how different parameters can scale while still guaranteeing consistent learning; essentially everything (including the dimension) should be subexponential in the number of samples.
Binning with Impunity for Distributed Hypothesis Testing
Md. Saifur Rahman and Aaron Wagner
This paper looked at a multiterminal source coding problem in which the two terminals observe 

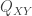

A small correction: in my setting, P is the distribution of the whole process, which in general is not IID.
See, and I was trying to figure out why I had written “dependent data” in my notes and underlined it. Ah, now I know.