I didn’t do such a great job of taking notes this time, but I went to a number of talks today. Maybe Max will blog too.
Tag Archives: statistics
Linkage
Another cool optical illusion.
I recently visited Taos, NM, and the sky there was clear and you could see so many stars. I was listening today to Debussy’s Arabesque #1 and it brought back memories of Jack Horkheimer‘s Star Hustler (c.f. this episode from 1991). Horkheimer passed away in 2010, but his show was a PBS staple.
A series of blog posts about quantiatively assessing if America is becoming more secular : Parts one, two, and three.
Ian Hacking’s introduction to the new edition of Thomas Kuhn’s The Structure of Scientific Revolutions (via MeFi).
More reasons to miss California. I do like Chicago, but… dumplings!
Readings
A Moveable Feast (Kenneth F. Kiple) : The first half is a somewhat condensed version of the Cambridge World History of Food and covers different plants and foodstuffs from around the world. The rest of the book is about how eating habits changed over time as food exchange has diversified and now homogenized our eating habits. The only problem with the book is that it has a fair bit of apocrypha and debunked origin stories, so YMMV. I enjoyed it.
Are You My Mother? (Alison Bechdel) : Bechdel’s memoir about her relationship with her mother. It is stuffed to the brim with references to D.W. Winnicott, which can be a plus or minus depending on whether you like psychoanalysis. I thought it was engaging and worth reading, but to be honest I am not sure to whom I would recommend it. I feel like if you read the synopsis and think it sounds interesting, you will like it, and if not, you won’t.
The Learners (Chip Kidd) : This is a follow-up to The Cheese Monkeys, which I rather enjoyed. The Learners is a little leaner but still has those nerdy and fun (to me, tedious to others) asides on the art of graphic design and typography. The Milgram experiment features prominently, so if you are fascinated by that you might also like this as a piece of (sort of) historical fiction.
This Is A Bust (Ed Lin) : A novel set in New York’s Chinatown in the 1970’s and featuring Vietnam vet and alcoholic token Chinese cop Robert Chow as he struggles to turn his life around and find himself. It’s the first in a series and I will probably read the rest. Recommended for those who like detective novels.
Fisher, Neyman, and the Creation of Classical Statistics (Erich L. Lehmann) : The title says it all. It’s more about the personalities and their history than it is particularly about the math, but there’s a nice discussion at the end of Fisher’s confusing notion of fiducial probability and Neyman’s confidence intervals. I think it’s hard to put yourself back in that time period when people really didn’t have a good sense of how to think about these kind of statistical problems (maybe we still don’t have a good idea). Fisher’s work has become near-dogma now (unfortunately), but it’s interesting to see how these basic frequentist methods came about historically. Plus you get to learn more about the enigmatic “Student!” Recommended for those with an interest in the history of statistics.
Readings
The Education of a British-Protected Child (Chinua Achebe) – A collection of essays over the years by noted Nigerian author Chinua Achebe. On the one hand, one might say he has a number of central issues he raises over and over again, but on the other, it might be said that he repeats himself. This is not surprising — these essays were written in different contexts and for different purposes (op-eds, speeches, and so on) and represent a set of concerns Achebe has about the relationship between himself and Nigeria, the Biafran conflict, Joseph Conrad, and the effects of colonialism. One of the more interesting pieces is a strong disagreement with Ngugi wa Thiong’o’s decision to write only in Gikuyu — Achebe views denying the use of English as a kind of sticking one’s fingers in one’s ears and saying “LALALALALALA.” Reading the collection, one is reminded that the easy distinctions we make here between revolutionary and conservative are just insufficient for understanding how one negotiates the legacy of colonialism. Worth a read!
The Taming of Chance (Ian Hacking) – A fantastic book and a must-read for those who care or are interested in the history of probability and statistical thought. A major point in the book is that as printing got cheaper and people were able to measure things, there was an explosion of publication of tables of counts — like how many loaves of bread were sold each week in a city, or the heights of soldiers, or… basically anything. People would survey and measure and publish all sorts of data. To make sense of this data deluge, people developed new ways of seeing populations in terms of aggregates. Individuals began to conceive of themselves in relation to the population. Notions of “statistical law” and “deviance” were a result of this process. It’s really fascinating stuff.
Tigana (Guy Gavriel Kay) — This book was extremely long and epic and I think would appeal to more literary minded Game of Thrones fans, but I found it too… consciously “aching” as it were. It’s a novel about loss and memory, and while that’s a rich field to plow, the book to me got a bit over-trodden (and overwritten).
Tomatoland (Barry Estabrook) — A rather depressing (but ultimately hopeful?) look at the tomato industry in Florida. Florida is not a great place to grow tomatoes, but it’s warm enough in the winter to supply mealy flavorless red baseballs to industrial kitchens further north. Estabrook spends a lot of time with the Coalition of Immokalee Workers, a group that tries to get better conditions for agricultural workers. You know, things like not being enslaved, or being paid by the hour instead of by the bucket, or not being sprayed with pesticides because growers don’t want to spend the time to clear the field of workers. Little things like that. It’s harrowing but worth reading.
Debt: The First 5,000 Years (David Graeber) — Graeber gives an engaging and far-ranging discussion of the notion of debt and credit. He’s trained as an anthropologist and has an axe to grind against economics. I found it to be an important book to read for anyone who cares about how we got to the society we have now. Some major theses : human relations are structured around communism (sharing), exchange, and hierarchy, and the interplay of these is complex and drives notions of debt. Credit systems have been around for a long time and in many cases predate “money” as we think of it. Current credit systems are backed by the coercive power of the state. People take issue with how starkly he puts the last point, but I think that as an anthropologist, Graeber has a much better vantage from which to look at and critique where we are now. It seems daunting, but he’s a clear expositor.
Linkage
Posting has been nonexistent this week due to being busy and incredibly tired. Hopefully the improved spring weather will thaw me out. On the upside, I’ve been reading more.
The ongoing problem of race in young adult literature (via Amitha Knight)
Speaking of race, the Chronicle of Higher Education published a piece mocking the whole field of Black Studies based on reading the titles of (proposed) dissertations (and a paragraph description). Tressie mc had a trenchant response. The faculty and students also responded.
And segueing from race via race and statistics (and eugenics), most of Galton’s works are now online.
Dirac’s thoughts on math and physics.
A touching film about 9/11 from Eusong Lee from CalArts.
If at first you don’t succeed, normalize, normalize again
My ex-groupmate and fellow Uni High graduate Galen Reeves told me about a paper a few weeks ago when I visited him at Stanford:
Successive Normalization of Rectangular Arrays
Richard A. Olshen and Bala Rajaratnam
The Annals of Statistics 38(3), pp.1369-1664, 2010
Apparently, however, the arguments in the paper are not quite correct [1], and they recently uploaded a correction to ArXiV.
This paper looks at the effect of a very common preprocessing step used to transform an 



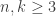
So what exactly is the preprocessing? I am going to describe things in pseudocode (too lazy to do real code, sorry). Given a data matrix X[i,j] they look at
for i = 1:n { X[i,1:k] = X[i,1:k] - sum(X[i,1:k]) }
for j = 1:k { X[1:n,j] = X[l:n,j] - sum(X[1:n,j]) }
They call the first a “row mean polish” and the second a “column mean polish.” They show this converges in one step.
But what about standardizing? The more complicated polishing procedure looks like this:
for i = 1:n {
mu = sum(X[i,1:k])
sigma = sqrt( sum( (X[i,1:k] - mu)^2 ) )
X[i,1:k] = (X[i,1:k] - mu)/sigma
}
for j = 1:k {
mu = sum(X[1:n,j])
sigma = sqrt( sum( (X[1:n,j] - mu)^2 ) )
X[1:n,j] = (X[1:n,j] - mu)/sigma
}
This standardizes rows first, and then columns (or “lather” and “rinse,” since we are going to “repeat”). They call this Efron‘s algorithm because he told them about it. So what happens if we repeat these two steps over and over again on a matrix with i.i.d. entries from some continuous distribution?
Theorem 4.1 Efron’s algorithm converges almost surely for X on a Borel set of entries with complement a set of Lebesgue measure 0.
So what does it look like in practice? How fast is this convergence? Empirically, it looks exponential, and they have some theoretical guarantees in the paper, kind of hidden in the discussion. The proofs are not terribly ornate but are tricky, and I don’t quite get all the details myself, but I figured readers of this blog would certainly be interested in this cute result.
[1] A fun quote from the paper “Theorem 4.1 of [2] is false. A claimed backwards martingale is NOT. Fortunately, all that seems damaged by the mistake is pride. Much is true.” I really liked this.
CISS 2012 : day 1
I’m at CISS right now on the magnolia-filled Princeton campus. The last time I came here was in 2008, when I was trying to graduate and was horribly ill, so this year was already a marked improvement. CISS bears some similarities to Allerton — there are several invited sessions in which the talks are a little longer than the submitted sessions. However, the session organizers get to schedule the entire morning or afternoon (3 hours) as they see fit, so hopping between sessions is not usually possible. I actually find this more relaxing — I know where I’m going to be for the afternoon, so I just settle down there instead of watching the clock so I don’t miss talk X in the other session.
Because there are these invited slots, I’ve begun to realize that I’ve seen some of the material before in other venues such as ITA. This is actually a good thing — in general, I’ve begun to realized that I have to see things 3 times for me to wrap my brain around them.
In the morning I went to Wojciech Szpankowski‘s session on the Science of Information, a sort of showcase for the new multi-university NSF Center. Peter Shor gave an overview of quantum information theory, ending with comments on the additivity conjecture. William Bialek discussed how improvements in array sensors for multi-neuron recording and other measurement technologies are allowing experimental verification of some theoretical/statistical approaches to neuroscience and communication in biological systems. In particular, he discussed an interesting example of how segmentation appears in the embryonic development of fruit flies and how they can track the propagation of chemical markers during development.
David Tse gave a slightly longer version of his ITA talk (with on DNA sequencing with more of the proof details. It’s a cute version of the genome assembly problem but I am not entirely sure what it tells us about the host of other questions biologists have about this data. I’m trying to wrestle with some short-read sequencing data to understand it (and learning some Bioconductor in the process), and the real data is pretty darn messy.
Madhu Sudan talked about his work with Brendan Juba (and now Oded Goldreich) on Semantic Communication — it’s mostly trying to come up with definitions of what it means to communicate meaning using computer science, and somehow feels like some of these early papers in Information and Control which tried to mathematize linguistics or other fields. This is the magical 3rd time I’ve seen this material, so maybe it’s starting to make sense to me.
Andrea Goldsmith gave a whirlwind tour of the work in backing away from asymptotic studies in information theory, and how insights we get from asymptotic analyses often don’t translate into the finite parameter regime. This is of a piece with her stand a few years ago on cross-layer design. High SNR assumptions in MIMO and relaying imply that certain tradeoffs (such diversity-multiplexing) or certain protocols (such as amplify-and forward) are fundamental but at moderate SNR the optimal strategies are different or unknown. Infinite blocklengths are the bread and butter of information theory but now there are more results on what we can do with finite blocklength. She ended with some comments on infinite processing power and trying to consider transmit and processing power jointly, which caused some debate in the audience.
Alas, I missed Tsachy Weissmann‘s talk, but at least I saw it at ITA? Perhaps I will get to see it two more times in the future!
In the afternoon I went to the large alphabets session which was organized by Aaron Wagner. Unfortunately, Aaron couldn’t make it so I ended up chairing the session. Venkat Chandrasekaran didn’t really talk about large alphabets, but instead about estimating high dimensional covariance matrices when you have symmetry assumptions on the matrix. These are represented by the invariance of the true covariance under actions of a subgroup of the symmetric group — taking these into account can greatly improve sample complexity bounds. Mesrob Ohanessian talked about his canonical estimation framework for large alphabet problems and summarized a lot of other work before (too briefly!) mentioning his own work on the consistency of estimators under some assumptions on the generating distribution.
Prasad Santhanam talked about the insurance problem that he worked on with Venkat Anantharam, and I finally understood it a bit better. Suppose you are observing i.i.d. samples 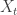


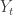

To round out the session, Wojciech Szpankowski gave a talk on analytic approaches to bounding minimax redundancy under different scaling assumptions on the alphabet and sample sizes. There was a fair bit of generatingfunctionology and Lambert W-functions. The end part of the talk was on scaling when you know part of the distribution exactly (perhaps through offline simulation or training) but then there is part which is unknown. The last talk was by Greg Valiant, who talked about his papers with Paul Valiant on estimating properties of distributions on 
I am not sure how much blogging I will do about the rest of the conference, but probably another post or two. Despite the drizzle, the spring is rather beautiful here — la joie du printemps.
Linkage
It’s been a while since I’ve posted, and I am going to try to post more regularly now, but as usual, things start out slowly, so here are some links. I’ve been working on massaging the schedule for the 2012 ITA Workshop (registration is open!) as well as some submissions for KDD (a first for me) and ISIT (since I skipped last year), so things are a bit hectic.
Chicago Restaurant Week listings are out, for the small number of you readers who are in Chicago. Some history on the Chicago activities of CORE in the 40s.
Via Andrew Gelman, a new statistics blog.
A paper on something called Avoidance Coupling, which I want to read sometime when I have time again.
Our team, Too Big To Fail, finished second in the 2012 MIT Mystery Hunt. There were some great puzzles in there. In particular, Picture An Acorn was awesome (though I barely looked at it), and Slash Fiction was a lot of fun (and nostalgia-inducing. Ah, Paris!). Erin has a much more exhaustive rundown.
Readings
I anticipate I will be doing a fair bit more reading in the future, due to the new job and personal circumstances. However, I probably won’t write more detailed notes on the books. This blog should be a rapidly mixing random walk, after all.
Embassytown (China Miéville) : a truly bizarre novel set on an alien world in on which humans have an Embassy but can only communicate with the local aliens in a language which defies easy description. Ambassadors come in pairs, as twins — to speak with the Ariekei they must both simultaneously speak (in “cut” and “turn”). The Ariekei’s language does not allow lying, and they have contests in which they try to speak falsehoods. However, events trigger a deadly change (I don’t want to give it away). Philosophically, the book revolves a lot around how language structures thought and perception, and it’s fascinating if you like to think about those things.
Chop Suey: A Cultural History of Chinese Food in the United States (Andrew Coe) : an short but engaging read about how Chinese food came to the US. The book starts really with Americans in China and their observations on Chinese elite banquets. A particular horror was that the meat came already chopped up — no huge roasts to carve. Chapter by chapter, Coe takes us through the railroad era through the 20s, the mass-marketing of Chinese food and the rise of La Choy, through Nixon going to China. The book is full of fun tidbits and made my flights to and from Seattle go by quickly.
The Thousand Autumns of Jacob de Zoet: A Novel (David Mitchell) : I really love David Mitchell’s writing, but this novel was not my favorite of his. It was definitely worth reading — I devoured it — but the subject matter is hard. Jacob de Zoet is a clerk in Dejima, a Dutch East Indies trading post in 19th century Japan. There are many layers to the story, and more than a hint of the grotesque and horrific, but Mitchell has an attention to detail and a mastery with perspective that really makes the place and story come alive.
Air (Geoff Ryman) : a story about technological change, issues of the digital divide, economic development, and ethnic politics, set in a village in fictional Karzistan (looks like Kazakhstan). Air is like having mandatory Internet in your brain, and is set to be deployed globally. During a test run in the village, Chung Mae, a “fashion expert,” ends up deep into Air and realizes that the technology is going to change their lives. She goes about trying (in a desperate, almost mad way) to tell her village and bring them into the future before it overwhelms them. There’s a lot to unpack here, especially in how technology is brought to rural communities in developing nations, how global capital and the “crafts” market impacts local peoples, and the dynamics of village social orders. It’s science fiction, but not really.
The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy (Sharon Bertsch McGrayne) : an engaging read about the history of Bayesian ideas in statistics. It reads a bit like an us vs. them, the underdog story of how Bayesian methods have overcome terrible odds (prior beliefs?) to win the day. I’m not sure I can give it as enthusiastic a review as Christian Robert, but I do recommend it as an engaging popular nonfiction read on this slice in the history of modern statistics. In particular, it should be entertaining to a general audience.
Dangerous Frames: How Ideas about Race and Gender Shape Public Opinion (Nicholas J.G. Winter) : the title says most of it, except it’s mostly about how ideas about race and gender shape white public opinion. The basic theoretical structure is that there are schemas that we carry that help us interpret issues, like a race schema or a gender schema. Then there are frames or narratives in which issues are put. If the schema is “active” and an issue is framed in a way that is concordant with the schema, then people’s opinions follow the schema, even if the issue is not “about” race or gender. This is because people reason analogically, so they apply the schema if it matches. To back up the theory, Winter has some experiments, both of the undergrads doing psych studies type as well as survey data, to show that by reframing certain issues people’s “natural” beliefs can be skewed by the schema that they apply. The schemas he discusses are those of white Americans, mostly, so the book feels like a bit of an uncomfortable read because he doesn’t really interrogate the somewhat baldly racist schemas. The statistics, as with all psychological studies, leaves something to be desired — I take the effects he notices at a qualitative level (as does he, sometimes).
A creepy but prescient quote
… statistical research accompanies the individual through his entire earthly existence. It takes account of his birth, his baptism, his vaccination, his schooling and the success thereof, his diligence, his leave of school, his subsequent education and development; and, once he becomes a man, his physique and his ability to bear arms. It also accompanies the subsequent steps of his walk through life; it takes note of his chosen occupation, where he sets up his household and his management of the same; if he saved from the abundance of his youth for his old age, if and when and at what age he marries and who he chooses as his wife — statistics looks after him when things go well for him and when they go awry. Should he suffer a shipwreck in his life, undergo material, moral or spiritual ruin, statistics take note of the same. Statistics leaves a man only after his death — after it has ascertained the precise age of his death and noted the causes that brought about his end.
Ernst Engel, 1862
