I started reading Convex Games in Banach Spaces, by Sridharan and Tewari and then got interested in the work of G. Pisier on martingales in Banach spaces, which studies how probability and geometry interact. Some of the definitions differ a bit between these papers (the former does things in terms of martingale difference sequences).
A Banach space 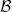 has Martingale-type
has Martingale-type  (or M-type ) if there is a constant
(or M-type ) if there is a constant  such that for any
such that for any  and -valued martingale
and -valued martingale  , we have
, we have
![\displaystyle \sup_{t} \mathop{\mathbb E}\left[ \left\| Y_t \right\| \right] \le C \left( \sum_{t=1}^{\infty} \mathop{\mathbb E}[ \left\| Y_t - Y_{t-1} \right\| ^p ] \right)^{1/p}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Csup_%7Bt%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cleft%5C%7C+Y_t+%5Cright%5C%7C+%5Cright%5D+%5Cle+C+%5Cleft%28+%5Csum_%7Bt%3D1%7D%5E%7B%5Cinfty%7D+%5Cmathop%7B%5Cmathbb+E%7D%5B+%5Cleft%5C%7C+Y_t+-+Y_%7Bt-1%7D+%5Cright%5C%7C+%5Ep+%5D+%5Cright%29%5E%7B1%2Fp%7D.+%09&bg=ffffff&fg=000000&s=0&c=20201002)
A Banach space has Martingale-cotype  (or M-cotype ) if there is a constant such that for any and -valued martingale , we have
(or M-cotype ) if there is a constant such that for any and -valued martingale , we have
![\displaystyle \left( \sum_{t=1}^{\infty} \mathop{\mathbb E}[ \left\| Y_t - Y_{t-1} \right\|^q ] \right)^{1/q} \le C \sup_{t} \mathop{\mathbb E}\left[ \left\| Y_t \right\| \right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09+%5Cleft%28+%5Csum_%7Bt%3D1%7D%5E%7B%5Cinfty%7D+%5Cmathop%7B%5Cmathbb+E%7D%5B+%5Cleft%5C%7C+Y_t+-+Y_%7Bt-1%7D+%5Cright%5C%7C%5Eq+%5D+%5Cright%29%5E%7B1%2Fq%7D+%09+%5Cle+%09+C+%5Csup_%7Bt%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cleft%5C%7C+Y_t+%5Cright%5C%7C+%5Cright%5D.+%09&bg=ffffff&fg=000000&s=0&c=20201002)
So far these are statements about how martingales behave in these spaces, and you can see a little geometry in the  kind of stuff, but how does this relate to overall geometric properties of the space?
kind of stuff, but how does this relate to overall geometric properties of the space?
A Banach space is reflexive if it is isomorphic to its double dual (the dual of its dual space). The space is reflexive if and only if its dual 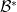 is reflexive. A space
is reflexive. A space 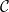 is finitely representable in if for any
is finitely representable in if for any  and any
and any  there exists an isomorphism
there exists an isomorphism  such that
such that

A Banach space is super-reflexive if no non-reflexive Banach space is finitely representable in . A result of James shows that a space is super-reflexive if and only if its dual is super-reflexive. Reflexivity means a space is “nice” and super-reflexivity is a kind of “uniform niceness.”
The norm for a Banach space is uniformly convex if for every  there exists a
there exists a 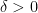 such that for two unit vectors
such that for two unit vectors  and
and  ,
,

implies

For example, for 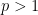 the spaces
the spaces 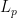 and
and  are uniformly convex. Another way to picture it is that if the midpoint of the chord between and is close to the surface of the unit ball, then the chord has to be short. Per Enflo showed that if a Banach space is super-reflexive, it has an equivalent norm which is uniformly convex.
are uniformly convex. Another way to picture it is that if the midpoint of the chord between and is close to the surface of the unit ball, then the chord has to be short. Per Enflo showed that if a Banach space is super-reflexive, it has an equivalent norm which is uniformly convex.
It turns out that the M-type is related to the degree of convexity of a space, namely how uniformly convex the norm is (and in turn connected to super-reflexivity). A space is –uniformly convex if

Gilles Pisier made the connection to M-types : a Banach space is super-reflexive if and only if it has M-type (or M-cotype  ). Furthermore, a Banach space has M-cotype if and only if has a -uniformly convex norm.
). Furthermore, a Banach space has M-cotype if and only if has a -uniformly convex norm.
So the big picture is this: super-reflexivity is enough to guarantee a uniformly convex norm, but the M-cotype characterizes the degree of how convex that norm is.
References:
Sridharan, Kartik and Tewari, Ambuj, Convex Games in Banach Spaces, Proceedings of COLT, 2010.
Enflo, Per, Banach spaces which can be given an equivalent uniformly convex norm, Israel Journal of Mathematics 13 (1972), 281-288.
James, Robert C., Super-reflexive Banach spaces., Canadian Journal of Mathematics 24 (1972), 896Ð904.
Pisier, Gilles, Probabilistic Methods in the Geometry of Banach spaces, in G. Letta and M. Pratelli, ed., Probability and Analysis, v.1206 of Lecture Notes in Mathematics, p167–241, Springer, 1986.
Pisier, Gilles, Martingales with values in uniformly convex spaces, Israel Journal of Mathematics 20 (1975), no. 3-4, 326Ð350.
Pisier, Gilles, Martingales in Banach Spaces (in connection with Type and Cotype), IHP Winter Course online lecture notes, 2011.
Lovaglia, A. R., Locally uniformly convex Banach spaces, Trans. Amer. Math. Soc. 78, (1955). 225Ð238.
 and
and  are close” into a statement about per-letter probabilities. Such a statement looks like “we can find some indices and values at those indices such that if we condition on those values, the marginals of
are close” into a statement about per-letter probabilities. Such a statement looks like “we can find some indices and values at those indices such that if we condition on those values, the marginals of  and
and  are close.” I’m going to skip straight to the simpler of the two “Wringing Lemmas” in this paper and sketch its proof. Then I’ll go back and state the first one (without proof). There are some small typos in the original which I will try to correct here.
are close.” I’m going to skip straight to the simpler of the two “Wringing Lemmas” in this paper and sketch its proof. Then I’ll go back and state the first one (without proof). There are some small typos in the original which I will try to correct here.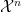 such that for a positive constant
such that for a positive constant  ,
, 
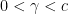 and
and  there exist
there exist  , where
, where 
 ,
, 
 and all
and all  . Furthermore,
. Furthermore, 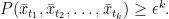
 and
and  . Suppose that the conclusion doesn’t hold for
. Suppose that the conclusion doesn’t hold for  . Then there is a
. Then there is a 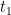 and
and  such that
such that 
 . Now dividing
. Now dividing  and using the lower bound on
and using the lower bound on  ,
, 
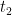 and a
and a  such that
such that 
 in the denominator. This yields the condition on
in the denominator. This yields the condition on  .
.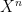 and
and  be
be  -tuples of random variables from discrete finite alphabets
-tuples of random variables from discrete finite alphabets 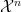 and
and 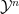 and assume that
and assume that 
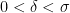 and there exist
and there exist 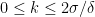
 ,
, 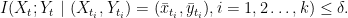

 and
and  be two distributions on a finite set
be two distributions on a finite set 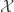 such that the KL-divergence
such that the KL-divergence  . Then there exists a sampling procedure which, when given a sequence of samples
. Then there exists a sampling procedure which, when given a sequence of samples 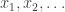 drawn i.i.d. according to
drawn i.i.d. according to  such that the sample
such that the sample  is distributed according to the distribution
is distributed according to the distribution 
 for all
for all 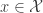 and set
and set  as well. Then for each
as well. Then for each  do the following:
do the following: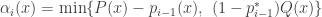



 with probability
with probability 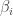 .
. is tracking the probability that the procedure halts at
is tracking the probability that the procedure halts at  (this is not entirely clear at first). Thus
(this is not entirely clear at first). Thus 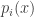 is the probability that we halted before time
is the probability that we halted before time  , and
, and  is the probability that we halt at time
is the probability that we halt at time  is the probability that the procedure gets to step
is the probability that the procedure gets to step  and we halt with probability
and we halt with probability  . So how should we define
. So how should we define  . However, we don’t want to let
. However, we don’t want to let  exceed the target probability
exceed the target probability  , so
, so  . The authors say that in this sense the procedure is greedy, since it tries to get
. The authors say that in this sense the procedure is greedy, since it tries to get  . This follows by induction. To get a bound on the description length of the output index, they have to show that
. This follows by induction. To get a bound on the description length of the output index, they have to show that![\mathbb{E}[ \log i^{\ast} ] \le D(P \| Q) + O(1)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%5Clog+i%5E%7B%5Cast%7D+%5D+%5Cle+D%28P+%5C%7C+Q%29+%2B+O%281%29&bg=ffffff&fg=333333&s=0&c=20201002) .
.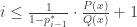
![\mathbb{E}[ \log i^{\ast} ] = \sum_{x} \sum_{i} \alpha_i(x) \cdot \log i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%5Clog+i%5E%7B%5Cast%7D+%5D+%3D+%5Csum_%7Bx%7D+%5Csum_%7Bi%7D+%5Calpha_i%28x%29+%5Ccdot+%5Clog+i&bg=ffffff&fg=333333&s=0&c=20201002) .
. drawn according to
drawn according to  according to the distribution
according to the distribution  . So ideally,
. So ideally,  have joint distribution
have joint distribution  . They can both generate a sequence of common
. They can both generate a sequence of common  according to the marginal distribution of
according to the marginal distribution of 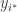 . How many bits does Alice have to send on average? It’s just
. How many bits does Alice have to send on average? It’s just![\mathbb{E}_{P(x)}[ D( P(y|x) \| P(y) ) + 2 \log( D( P(y|x) \| P(y) ) + 1) + O(1) ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BP%28x%29%7D%5B+D%28+P%28y%7Cx%29+%5C%7C+P%28y%29+%29+%2B+2+%5Clog%28+D%28+P%28y%7Cx%29+%5C%7C+P%28y%29+%29+%2B+1%29+%2B+O%281%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.![I(X ; Y) + 2 \log( I(X; Y) + 1) + O(1) ]](https://s0.wp.com/latex.php?latex=I%28X+%3B+Y%29+%2B+2+%5Clog%28+I%28X%3B+Y%29+%2B+1%29+%2B+O%281%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.