I recently read a paper from STOC 2011 by Doerr, Fouz, and Friedrich on rumor spreading in preferential attachment graphs: Social networks spread rumors in sublogarithmic time, and it cites a 2004 paper by Bollob´s and Riordan from Combinatorica on The diameter of a scale-free random graph (i.e. a preferential attachment graph). The latter paper has a characterization of the graph growth process which is fun and geometric, so I thought it might make a good topic for a post.
So what is a preferential attachment graph? The graph has parameters 

for i = 2 to n
add vertex i
for t = 1 to m
d <- degrees of vertices
d(i) <- d(i) + 1
pick vertex j with probability d(j)/sum(d)
add edge (i,j)
The idea is that we add each vertex 

The problem is that this process, while easy to code up and simulate, is rather annoying to analyze, since it goes in this sequential way and things are kind of messy. So what Bollob´s and Riordan do is to look at a different way of generating the same random graph. They prove that the two processes are equivalent in their paper, but here I’ll just show what it looks like graphically.
As Doerr et al. note, it’s easier to think of this first for 

![{[0,1]\times[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%5Ctimes%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Then reorder the pairs so 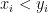
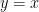
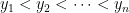

Note that we could have just picked 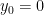



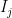




Ok but what about for larger 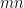
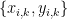
![{[0,1] \times [0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

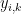
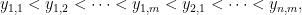
and set 




Very cute! :-)
I am curious now — what is an example of a theorem that is easier to prove because you look at the graph this way?
Bollobás and Riordan get results showing the intervals satisfy some properties that hold w.h.p. for large n. So we can think of the graph as kind of having static edge probabilities rather than worrying about this dynamic graph growing process blah blah.