My collaborator Staal Vinterbo has written an implementation in R of differentially private logistic regression and put it into a package on the CRAN archive. It implements the objective perturbation method described in this paper.
Tag Archives: privacy
Linkage
I’ve been refraining from talking about the Dharun Ravi case, because it’s pretty complicated. On the one hand, after reading the New Yorker article and other material, it’s pretty clear Dharun is a grade-A jerk. And Tyler Clementi’s death was a terrible tragedy. But on the other hand, 10 years in prison is a serious thing, as Ta-Nehisi Coates points out. Ashvin shared a link to a blog post on “Deporting Homophbia”:
I have been Tyler and Dharun in a post 9/11 U.S. that accuses white men of exploiting the rest of the world and accuses brown men of destroying it. I have been Tyler and Dharun in a post 9/11 world where white men advocate for homosexual rights and advance homophobia and where brown men are understood as always homophobic. I am being presumptuous, so let me stop.
It’s an interesting take on things, and has made me think about the media coverage of the event and if and how Dharun’s race has played into how the story has been told.
Via Kamalika I learned about a lawsuit against IMDB.
A gem from SMBC via Cosma. The Beef Tensors are a nice touch.
Sepia Mutiny is shutting down, and Amardeep has some closing thoughts.
We always get to hear these stories about how service providers needs differential pricing for network traffic because they can’t make money, but then stories like this make me question the integrity of the complainers.
I heard Of Monsters and Men on KEXP and their show is sold out in Chicago, boo. Here’s their crazy video though:
ICITS Deadline Extension
Due to conflicts with other deadlines and conferences, the submission
deadline for the “conference” track of ICITS 2012 — the International
Conference on Information-Theoretic Security — has been moved back
ten days to Thursday, March 22, 2012.
The “conference” deadline is now Thursday, March 22 (3pm EDT / 19:00 GMT).
The “workshop” deadline is Monday, April 9.
ICITS will have two tracks this year, one which will act as a regular
computer science-style conference (published proceedings, original
work only) and the other which will behave more like a workshop,
without proceedings, where presentations on previously published work
or work in progress are welcome.
For more information, see the conference website.
Postdoc position in differential privacy
There’s a new postdoc position open in a new interdisciplinary center to work on overcoming practical challenges to implementing differential privacy. Having started work in this area myself, I definitely think there are a number of interesting (and difficult) practical considerations faced by data-holders that the existing literature is just starting to touch upon.
ITA Workshop 2012 : More Talks
There are some more talks to blog about, probably, but I am getting lazy, and one of them I wanted to mention was Max’s, but he already blogged a lot of it. I still don’t get what the “Herbst argument” is, though.
Vinod Prabhakaran gave a talk about indirect decoding in the 3-receiver broadcast channel. In indirect decoding, there is a “semi-private” message that is not explicitly decoded by the third receiver. However, Vinod argued that this receiver can decoded it anyway, so the indirectness is not needed, somehow. At least, that’s how I understood the talk.
Lalitha Sankar talked about two different privacy problems that could arise in “smart grid” or power monitoring situations. The first is a model of system operators (ISOs) and how to view the sharing of load information — there was a model of 
Negar Kiyavash talked about timing side channel attacks — an adversary can ping your router and from the delays in the round trip times can learn pretty much what websites you are surfing. Depending on the queueing policy, the adversary can learn more or less about you. Negar showed that first come first serve (FCFS) is terrible in this regard, and there is a bit of a tradeoff wherein policies with higher delay offer more privacy. This seemed reminiscent of the work Parv did on Chaum mixing…
Lav Varshney talked about security in RFID — the presence of an eavesdropper actually detunes the RFID circuit, so it may be possible for the encoder and decoder to detect if there is an eavesdropper. The main challenge is that nobody knows the transfer function, so it has to be estimated (using a periodogram energy detector). Lav proposed a protocol in which the transmitter sends a key and the receiver tries to detect if there is an eavesdropper; if not, then it sends the message.
Tsachy Weissman talked about how to estimate directed mutual information from data. He proposed a number of estimators of increasing complexity and showed that they were consistent. The basic idea was to leverage all of the results on universal probability estimation for finite alphabets. It’s unclear to me how to extend some of these results to the continuous setting, but this is an active area of research. I saw a talk recently by John Lafferty on forest density estimation, and this paper on estimating mutual information also seems relevant.
ITA Workshop 2012 : Talks
The ITA Workshop finished up today, and I know I promised some blogging, but my willpower to take notes kind of deteriorated during the week. For today I’ll put some pointers to talks I saw today which were interesting. I realize I am heavily blogging about Berkeley folks here, but you know, they were interesting talks!
Nadia Fawaz talked about differential privacy for continuous observations : in this model you see 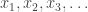

David Tse gave an interesting talk about sequencing DNA via short reads as a communication problem. I had actually had some thoughts along these lines earlier because I am starting to collaborate with my friend Tony Chiang on some informatics problems around next generation sequencing. David wanted to know how many (noiseless) reads 



Michael Jordan talked about the “big data bootstrap” (paper here). You have 

Anant Sahai talked about how to look at some decentralized linear control problems as implicitly doing some sort of network coding in the deterministic model. One way to view this is to identify unstable modes in the plant as communicating with each other using the controllers as relays in the network. By structurally massaging the control problem into a canonical form, they can make this translation a bit more formal and can translate results about linear stabilization from the 80s into max-flow min-cut type results for network codes. This is mostly work by Se Yong Park, who really ought to have a more complete webpage.
Paolo Minero talked about controlling a linear plant over a rate-limited communication link whose capacity evolves according to a Markov chain. What are the conditions on the rate to ensure stability? He made a connection to Markov jump linear systems that gives the answer in the scalar case, but the necessary and sufficient conditions in the vector case don’t quite match. I always like seeing these sort of communication and control results, even though I don’t work in this area at all. They’re just cool.
There were three talks on consensus in the morning, which I will only touch on briefly. Behrouz Touri gave a talk about part of his thesis work, which was on the Hegselman-Krause opinion dynamics model. It’s not possible to derive a Lyapunov function for this system, but he found a time-varying Lyapunov function, leading to an analysis of the convergence which has some nice connections to products of random stochastic matrices and other topics. Ali Jadbabaie talked about work with Pooya Molavi on non-Bayesian social learning, which combines local Bayesian updating with DeGroot consensus to do distributed learning of a parameter in a network. He had some new sufficient conditions involving disconnected networks that are similar in flavor to his preprint. José Moura talked about distributed Kalman filtering and other consensus meets sensing (consensing?) problems. The algorithms are similar to ones I’ve been looking at lately, so I will have to dig a bit deeper into the upcoming IT Transactions paper.
A creepy but prescient quote
… statistical research accompanies the individual through his entire earthly existence. It takes account of his birth, his baptism, his vaccination, his schooling and the success thereof, his diligence, his leave of school, his subsequent education and development; and, once he becomes a man, his physique and his ability to bear arms. It also accompanies the subsequent steps of his walk through life; it takes note of his chosen occupation, where he sets up his household and his management of the same; if he saved from the abundance of his youth for his old age, if and when and at what age he marries and who he chooses as his wife — statistics looks after him when things go well for him and when they go awry. Should he suffer a shipwreck in his life, undergo material, moral or spiritual ruin, statistics take note of the same. Statistics leaves a man only after his death — after it has ascertained the precise age of his death and noted the causes that brought about his end.
Ernst Engel, 1862
HealthSec 2011
I also attended HealthSec ’11 this week, and the program was a little different than what I had expected. There was a mix of technical talks and policy/framework proposals around a couple of themes:
- security in medical devices
- auditing in electronic medical records
- medical record dissemination and privacy
In particular, a key challenge in healthcare coming up is how patient information is going to be handled in heath insurance exchanges (HIE’s) that will be created as part of the Affordable Care Act. The real question is what is the threat model for health information : hackers who want to wholesale health records, or the selling of data by third parties (e.g. insurance companies). Matthew Green from Dartmouth discussed implications of the PCAST report on Health Information Technology, which I will have to read.
The most interesting part of the workshop was the panel on de-identification and whether it was a relevant or useful framework moving forward. The panelists were Sean Nolan from Microsoft, Kelly Edwards from University of Washington, Arvind Narayanan from Stanford, and Lee Tien from the EFF. Sean Nolan talked a bit about how HIPAA acts as an impediment to exploratory research, which I have worked on a little, but also raised the thorny ethical issue of public good versus privacy, which is key to understanding the debate over health records in clinical research. Edwards is a bioethicist and had some very important points to raise about how informed consent is an opportunity to educate patients about their (potential) role in medical research, but also to make them feel like informed participants in the process. The way in which we phrase the tradeoff Nolan mentioned really relates to ethics in how we communicate the tradeoff to patients. Narayanan (famous for his Netflix deanonymization) talked about the relationship between technology and policy has to be rethought or turned more into a dialogue rather than a blame-shifting or challenge-posing framework. Lee Tien made a crucial point that if we do not understand how patient data moves about in our existing system, then we have no hope of reform or regulation, and no stakeholder in the system how has that “bird’s eye view” of these data flows.
I hope that in the future I can contribute to this in some way, but in the meantime I’ve been left with a fair bit to chew on. Although the conference was perhaps a bit less technical than I would have liked, I think it was quite valuable as a starting point for future work.
Linkage
I’m blogging from Chicago, where it is a balmy 42 degrees but sunny. Whither spring, I ask! Actually, I’m not blogging so much as linking to a bunch of stuff.
For San Diegans, the SD Asian Film Festival Spring Showcase is going on. It looks like I’ll miss a lot of it but I might try to catch something at the end of the week.
Less Pretentious & More Accurate Titles For Literary Masterworks — funny but possibly NSFW.
This home-scanning program seems creepy, regardless of the constitutionality issues.
Unfortunate headlines strike again.
I really like scallion pancakes. I’ll have to try this out when I get back to San Diego.
I agree that this video is awesome. Yo-Yo Ma and Lil Buck. I think that dude is made of rubber. And steel.
Tom Waits was induced into the Rock and Roll Hall of Fame. I just hope I get to see him live some day.
Some things to skim or read from ArXiV when I get the chance:
Sequential Analysis in High Dimensional Multiple Testing and Sparse Recovery (Matt Malloy, Robert Nowak)
Differential Privacy: on the trade-off between Utility and Information Leakage (Mário S. Alvim, Miguel E. Andrés, Konstantinos Chatzikokolakis, Pierpaolo Degano, Catuscia Palamidessi)
Capacity of Byzantine Consensus with Capacity-Limited Point-to-Point Links (Guanfeng Liang, Nitin Vaidya)
Settling the feasibility of interference alignment for the MIMO interference channel: the symmetric square case (Guy Bresler, Dustin Cartwright, David Tse)
Decentralized Online Learning Algorithms for Opportunistic Spectrum Access (Yi Gai, Bhaskar Krishnamachari)
Online and Batch Learning Algorithms for Data with Missing Features (Afshin Rostamizadeh, Alekh Agarwal, Peter Bartlett)
Nonuniform Coverage Control on the Line (Naomi Ehrich Leonard, Alex Olshevsky)
Degree Fluctuations and the Convergence Time of Consensus Algorithms (Alex Olshevsky, John Tsitsiklis)
Privacy and entropy (needs improvement)
A while ago, Alex Dimakis sent me an EFF article on information theory and privacy, which starts out with an observation of Latanya Sweeney’s that gender, ZIP code, birthdate are uniquely identifying for a large portion of the population (an updated observation was made in 2006).
What’s weird is that the article veers into “how many bits of do you need to uniquely identify someone” based on self-information or surprisal calculations. It paints a bit of a misleading picture about how to answer the question. I’d probably start with taking 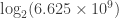
However, the mere existence of this article raises a point : here is a situation where ideas from information theory and probability/statistics can be made relevant to a larger population. It’s a great opportunity to popularize our field (and demonstrate good ways of thinking about it). Why not do it ourselves?
