There are some more talks to blog about, probably, but I am getting lazy, and one of them I wanted to mention was Max’s, but he already blogged a lot of it. I still don’t get what the “Herbst argument” is, though.
Vinod Prabhakaran gave a talk about indirect decoding in the 3-receiver broadcast channel. In indirect decoding, there is a “semi-private” message that is not explicitly decoded by the third receiver. However, Vinod argued that this receiver can decoded it anyway, so the indirectness is not needed, somehow. At least, that’s how I understood the talk.
Lalitha Sankar talked about two different privacy problems that could arise in “smart grid” or power monitoring situations. The first is a model of system operators (ISOs) and how to view the sharing of load information — there was a model of 
Negar Kiyavash talked about timing side channel attacks — an adversary can ping your router and from the delays in the round trip times can learn pretty much what websites you are surfing. Depending on the queueing policy, the adversary can learn more or less about you. Negar showed that first come first serve (FCFS) is terrible in this regard, and there is a bit of a tradeoff wherein policies with higher delay offer more privacy. This seemed reminiscent of the work Parv did on Chaum mixing…
Lav Varshney talked about security in RFID — the presence of an eavesdropper actually detunes the RFID circuit, so it may be possible for the encoder and decoder to detect if there is an eavesdropper. The main challenge is that nobody knows the transfer function, so it has to be estimated (using a periodogram energy detector). Lav proposed a protocol in which the transmitter sends a key and the receiver tries to detect if there is an eavesdropper; if not, then it sends the message.
Tsachy Weissman talked about how to estimate directed mutual information from data. He proposed a number of estimators of increasing complexity and showed that they were consistent. The basic idea was to leverage all of the results on universal probability estimation for finite alphabets. It’s unclear to me how to extend some of these results to the continuous setting, but this is an active area of research. I saw a talk recently by John Lafferty on forest density estimation, and this paper on estimating mutual information also seems relevant.
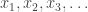 causally and have to estimate the running sum. She had two modifications, one in which you only want a windowed running sum, say for
causally and have to estimate the running sum. She had two modifications, one in which you only want a windowed running sum, say for  past values, and one in which the privacy constraint decays and expires after a window of time
past values, and one in which the privacy constraint decays and expires after a window of time  you need to take of a genome of of length
you need to take of a genome of of length  using reads of length
using reads of length  . It turns out that the correct scaling in this model is
. It turns out that the correct scaling in this model is  . Some scaling results were given in a qualitative way, but I guess the quantitative stuff is being written up still.
. Some scaling results were given in a qualitative way, but I guess the quantitative stuff is being written up still. data points, where
data points, where  and then do bootstrap estimates of size
and then do bootstrap estimates of size  between two random variables
between two random variables  and
and  is
is ![\sup_{f \in \mathcal{F}_X, g \in \mathcal{G}_Y} \mathbb{E}[ f(X) g(Y) ]](https://s0.wp.com/latex.php?latex=%5Csup_%7Bf+%5Cin+%5Cmathcal%7BF%7D_X%2C+g+%5Cin+%5Cmathcal%7BG%7D_Y%7D+%5Cmathbb%7BE%7D%5B+f%28X%29+g%28Y%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
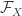 is all real-valued functions such that
is all real-valued functions such that ![\mathbb{E}[ f(X) ] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f%28X%29+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![\mathbb{E}[ f(X)^2 ] = 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+f%28X%29%5E2+%5D+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002) and
and 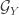 is all real valued functions such that
is all real valued functions such that ![\mathbb{E}[ g(Y) ] = 0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+g%28Y%29+%5D+%3D+0&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![\mathbb{E}[ g(Y)^2 ] = 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+g%28Y%29%5E2+%5D+%3D+1&bg=ffffff&fg=333333&s=0&c=20201002) . It’s a cool measure of dependence that covers discrete and continuous variables, since they all get passed through these “normalizing”
. It’s a cool measure of dependence that covers discrete and continuous variables, since they all get passed through these “normalizing”  and
and  functions.
functions. .
. .
.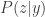 ) and not the actual data processing
) and not the actual data processing  which is given to you.
which is given to you.