This is the penultimate post on papers I saw at ISIT 2009 that I thought were interesting and on which I took some notes. I think I’m getting lazier and lazier with the note taking — I went to lots more talks than these, but I’m only writing about a random subset.
Existence and Construction of Capacity-Achieving Network Codes for Distributed Storage
Yunnan Wu
This paper looked at the distributed storage problem using the framework of network coding that Alex has worked on. The basic idea is that you have a bunch of drives redundantly storing some information (say n drives and you can query any k to reconstruct the data). You want to make it so that if any drive fails, it can be replaced by a new drive so that the new drive doesn’t have to download too much data to maintain the “k out of n” property. The problem can be translated into a network code on an infinite graph. This paper talked about how to achieve the optimal tradeoff between the bandwidth needed to repair the code and the storage efficiency/redundancy. The key thing is that even though the network graph is infinite, the network code can be constructed over a field whose size only depends on the number of active disks. Schwartz-Zippel reared its head again in the proof…
Achievability Results for Statistical Learning under Communication Constraints
Maxim Raginsky
This talk was on how to learn a classifier when the data-label pairs 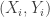 must be compressed. Max talked about two different scenarios, one in which you can use
must be compressed. Max talked about two different scenarios, one in which you can use  bits per pair, and the other in which only the labels
bits per pair, and the other in which only the labels 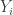 must be sent. He defined a rate-distortion-like function where the generalization error the classifier played the role of the distortion. In the first case it’s easier for the encoder to learn the classifier itself and send the classifier over — this takes 0 bits per sample, asympotically, and incurs no extra generalization error. In the second case he uses a kind of Wyner-Ziv-like scheme which is a bit more involved. Compression is not a thing many machine learning folks think about, so I think there’s a lot of interesting stuff in this direction.
must be sent. He defined a rate-distortion-like function where the generalization error the classifier played the role of the distortion. In the first case it’s easier for the encoder to learn the classifier itself and send the classifier over — this takes 0 bits per sample, asympotically, and incurs no extra generalization error. In the second case he uses a kind of Wyner-Ziv-like scheme which is a bit more involved. Compression is not a thing many machine learning folks think about, so I think there’s a lot of interesting stuff in this direction.
On Feedback in Network Source Coding
Mayank Bakshi, Michelle Effros
This paper was about how feedback can help in distributed source coding. In some lossless and lossy problems, feedback can strictly increase the rate region. Some of these problems took the form of “helper” scenarios where the decoder wants one of the sources but gets coded side information from another source. They show that this scenario holds more generally, and so feedback helps in general in network source coding.
Feedback Communication over Individual Channels
Power Adaptive Feedback Communication over an Additive Individual Noise Sequence Channel
Yuval Lomnitz, Meir Feder
These talks were near and dear to my heart since they dealt with coding over channels which are basically unknown. The basic idea is that you know only 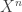 and
and  , the inputs and outputs of the channel. The trick is then to define a corresponding “achievable rate.” They define an empirical mutual information and show that it is asymptotically achievable under some circumstances. The scheme is based on random coding plus maximum mutual information (MMI) decoding. When feedback is present they can do some rateless coding. There’s a full version on ArXiV.
, the inputs and outputs of the channel. The trick is then to define a corresponding “achievable rate.” They define an empirical mutual information and show that it is asymptotically achievable under some circumstances. The scheme is based on random coding plus maximum mutual information (MMI) decoding. When feedback is present they can do some rateless coding. There’s a full version on ArXiV.
Upper Bounds to Error Probability with Feedback
Barış Nakiboğlu, Lizhong Zheng
Baris gave a nice talk on his approach to modifying the Gallager exponent bounds to the case when feedback is available. The encoder constantly adapts to force the decoder into a decision. The upper bound is based on a one-step/channel-use reduction to show an exponentially decaying error probability. One nice thing he mentioned is that at rates below capacity we can get a better error exponent by not using the capacity-achieving input distribution. Even though I read the paper and Barış explained it to me very patiently, I still don’t quite get what is going on here. That’s probably because I never really worked on error exponents…


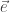 it can detect all signals whose support is the same as
it can detect all signals whose support is the same as  with an iid process (say equiprobable coin flips)
with an iid process (say equiprobable coin flips)  . Using the
. Using the  and
and  . If the entropy spectrum in
. If the entropy spectrum in  are the number of bits in each chunk). How do you size the chunks to maximize the volume? This can be solved with dynamic programming. There are still several open questions left, but the whole construction relies on using “optimal codes of finite blocklength” which also needs to be solved. Lav has some interesting ideas along these lines that he told me about when I was in Boston two weeks ago…
are the number of bits in each chunk). How do you size the chunks to maximize the volume? This can be solved with dynamic programming. There are still several open questions left, but the whole construction relies on using “optimal codes of finite blocklength” which also needs to be solved. Lav has some interesting ideas along these lines that he told me about when I was in Boston two weeks ago…  constraints. Achievability uses Han-Kobayashi in a block-Markov encoding with backward decoding, and the converse uses the El Gamal-Costa argument with some additional Markov properties. For the “bit-level” deterministic channel model, there is an interpretation of the feedback as filling a “hole” in the interference graph.
constraints. Achievability uses Han-Kobayashi in a block-Markov encoding with backward decoding, and the converse uses the El Gamal-Costa argument with some additional Markov properties. For the “bit-level” deterministic channel model, there is an interpretation of the feedback as filling a “hole” in the interference graph. and
and  . The pairs
. The pairs  . As an example,
. As an example, 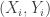 could be correlated bits and
could be correlated bits and 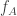 and
and 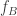 could be the AND function. In previous work the authors characterized the the rate region (allowing vanishing probability of error) for
could be the AND function. In previous work the authors characterized the the rate region (allowing vanishing probability of error) for  rounds of communication, and here they look at the case when there are infinitely many back-and-forth messages. The key insight is to characterize the sum-rate needed as a function of
rounds of communication, and here they look at the case when there are infinitely many back-and-forth messages. The key insight is to characterize the sum-rate needed as a function of 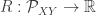 and look at that surface’s analytic properties. In particular, they show it’s the minimum element of a class
and look at that surface’s analytic properties. In particular, they show it’s the minimum element of a class  of functions which have some convexity properties. There is a
of functions which have some convexity properties. There is a 

 , where the realized state sequence is known ahead of time at the encoder. The first paper proved a technical lemma about the image size of “good codeword sets” which are jointly typical conditioned on a large subset of the typical set of
, where the realized state sequence is known ahead of time at the encoder. The first paper proved a technical lemma about the image size of “good codeword sets” which are jointly typical conditioned on a large subset of the typical set of 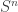 sequences. That is, given a code and a set of almost
sequences. That is, given a code and a set of almost 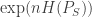 typical sequences in
typical sequences in 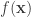 from long binary strings
from long binary strings 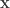 so that a verifier can look at a new long vector
so that a verifier can look at a new long vector 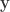 and tell whether or not
and tell whether or not 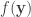 . They develop a scheme which stores the index of a reference vector
. They develop a scheme which stores the index of a reference vector  that is “close” to
that is “close” to  . This can be done with low complexity. They calculated false accept and reject rates for this scheme. Since the goal is not reconstruction or approximation, but rather a kind of classification, they can derive a reference vector set which has very low rate.
. This can be done with low complexity. They calculated false accept and reject rates for this scheme. Since the goal is not reconstruction or approximation, but rather a kind of classification, they can derive a reference vector set which has very low rate. users and the decoder wants to detect which users transmitted. The users are each “on” with some fixed probability, and they show this can be put into a sparsity detection framework. There are two problems to overcome — the near-far effect of large dynamic range of the received signals, and a “multiaccess interference” (MAI) phenomenon that plagues most detection algorithms, including the Lasso and orthogonal matching pursuit (OMP). The question is whether a practical algorithm can overcome these effects — they show that a modification of OMP can do so as long as the decoder knows some additional information about the received signals, namely the power profile which is the order of the users’ power, conditional that they are active.
users and the decoder wants to detect which users transmitted. The users are each “on” with some fixed probability, and they show this can be put into a sparsity detection framework. There are two problems to overcome — the near-far effect of large dynamic range of the received signals, and a “multiaccess interference” (MAI) phenomenon that plagues most detection algorithms, including the Lasso and orthogonal matching pursuit (OMP). The question is whether a practical algorithm can overcome these effects — they show that a modification of OMP can do so as long as the decoder knows some additional information about the received signals, namely the power profile which is the order of the users’ power, conditional that they are active.