It is a gorgeous fall day here at the park. Almost seems a pity to be hiding in the lower level…

It is a gorgeous fall day here at the park. Almost seems a pity to be hiding in the lower level…
On Saturday I attended the 2nd iDASH workshop on privacy — I thought overall it went quite well, and it’s certainly true that over the last year the dialogue and understanding has improved between the theory/algorithms, data management/governance, and medical research communities. I developed note fatigue partway through the day, but I wanted to blog a little bit about some of the themes which came up during the workshop. Instead of making a monster post which covers everything, I will touch on a few things here. In particular, there were other talks not mentioned below about issues in data governance, cryptographic approaches, special issues in genomics, study design, and policy. I may touch on those in later posts.
Cynthia Dwork and Latanya Sweeney gave the keynotes, as they did last year, and they dovetailed quite nicely this year. Cynthia’s talk centered on how to think of privacy risk in terms of resource allocation — you have a certain amount of privacy and you have to apportion it over multiple queries. Latanya Sweeney’s talk came from the other direction: the current legal framework in the US is designed to make information flow, and so it is already a privacy-unfriendly policy regime. These raise some serious impediments to practically implementing privacy protections that we develop on the technological side.
On the privacy models side, Ashwin Machanavajjhala, Chris Clifton talked about slightly different models of privacy that are based on differential privacy but have a less immediately statistical feel, based on work from PODS 2012 and KDD 2012. Kamalika Chaudhuri talked about our work on differentially private PCA, and Li Xiong talked about differential privacy on time series using adaptive sampling and prediction.
Guy Rothblum talked about something he called “concentrated differential privacy,” which essentially amounts to analyzing the measure concentration properties of the log-likelihood ratio that appears in the differential privacy definition : for any two databases 
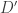


Via Kamalika, I head about the DIMACS Workshop on differential privacy at the end of October:
DIMACS Workshop on Differential Privacy across Computer Science
October 24-26, 2012
(immediately after FOCS 2012)Call for Abstracts — Short Presentations
The upcoming DIMACS workshop on differential privacy will feature invited talks by experts from a range of areas in computer science as well as short talks (5 to 10 minutes) by participants.
Participants interested in giving a short presentation should send an email to asmith+dimacs@psu.edu containing a proposed talk title, abstract, and the speaker’s name and affiliation. We will try to
accommodate as many speakers as possible, buta) requests received before October 1 will get full consideration
b) priority will be given to junior researchers, so students and postdocs should indicate their status in the email.More information about the workshop:
The last few years have seen an explosion of results concerning differential privacy across many distinct but overlapping communities in computer science: Theoretical Computer Science, Databases, Programming Languages, Machine Learning, Data Mining, Security, and Cryptography. Each of these different areas has different priorities and techniques, and despite very similar interests, motivations, and choice of problems, it has become difficult to keep track of this large literature across so many different venues. The purpose of this workshop is to bring researchers in differential privacy across all of these communities together under one roof to discuss recent results and synchronize our understanding of the field. The first day of the workshop will include tutorials, representing a broad cross-section of research across fields. The remaining days will be devoted to talks on the exciting recent results in differential privacy across communities, discussion and formation of interesting open problems, and directions for potential inter-community collaborations.
The workshop is being organized by Aaron Roth (blog) and Adam Smith (blog).
The Allerton 2012 early registration deadline is this Friday. I tried registering at the link they sent but found I had to click on the “submit a paper” button on the main PaperCept page, so YMMV.
When I moved to Chicago I realized I had a ton of conference bags. I was lucky enough to have a large closet in San Diego, and they kind of piled up in a back corner, from various ISITs and so on. I gave a few to Goodwill, but I have no idea if they will get used. I was recently talking to folks who work in public health and they were shocked that we get these “nice” bags at conferences — they get water bottles. Computer science conferences give out shirts. Why do we get bags? It’s kind of a pet peeve of mine, for a number of reasons.
How much do these bags cost? I should find this out, but I imagine a full messenger bag with laptop sleeve (c.f. ISIT 2012) isn’t cheap, and that cost gets directly transferred to registration fees. It probably only works out to 20 bucks but still…
Why don’t we get pens and paper? Most of the time you get a bag, a USB stick with the proceedings, the program booklet… and that’s it. I was shocked at SPCOM in Bangalore that they gave us a spiral notebook (handy!) and a pen (and really nice one at that) on *top* of the bag (which is pretty nice, as backpacks go).
Don’t people already have bags? You’re traveling halfway around the world with your laptop. You must have some sort of bag that you use already — why do you need another one? How are you going to fit it into your luggage?
Of course, after thinking of these complaints it turns out my ISIT 2012 bag has been a lifesaver — my apartment was robbed and they took all of my computers and electronics and carried them off in my bag, so having a ready replacement sure was handy. Furthermore, I use the tote bags (ISIT 2007-2009) all the time for groceries or going to the gym or the beach, so those are great.
What kind of schwag would you prefer? I use my IPSN 2005 mug all the time at work for tea…

After a fun trip to Mysore this weekend, I have landed at the Indian Institute of Science in Bangalore (Bengaluru for those more PC), for SPCOM 2012. This is a 4 day conference (yesterday was tutorials) that has been held 8 times before (sometimes skipping years) here at IISc. I’ve never visited here before, but my father, grandfather, and great grandfather are all graduates, so it feels pretty special to finally see the place. My talk is dead last, so we’ll see how many people are still here by the time it rolls around.
We are at ISIT and I realize I am going over the same points multiple times with my students, so I thought of summarizing everything here.
How to give a better ISIT Talk.
1. Take your talks very seriously.
Do practice runs. Many of them. Your only hope for academia is by giving great talks. Give a practice talk to your friends. In the middle of your talk pause and quiz them: ok, did you get why alpha and beta are not independent? (hint: they did not).
If they did not, it is your problem not their problem.
2. They do not remember what alpha is.
In most talks, your audience does not understand what the notation is, what the problem is, or why they should care. Think of yourself: how often do you sleep or suffer through talks without even knowing what the problem is?
Do not treat your audience like that.
It is a typical scene when the presenter is focusing on a minor technical issue for ten minutes when 90% of the audience does not even know what exactly the problem is, or care.
One important exception is when your audience works on the same problem. Typically only a small part of your talk should be focused on these experts (see also 13).
3. Do a multi-resolution talk.
A useful guideline is: for an 18 minute talk, 7-9 minutes should go on explaining the formulation of your problem and why should anybody care. 5-6 minutes on explaining *what* the solution is and 4 minutes or so, on the actual painful technical stuff. The first part should be aimed at a first year grad student level. The second at a senior grad student in the general ISIT area and the last part to the expert working on related problems. If fewer than 90% of your audience are checking email in the last part of your talk, consider that a success.
4. Try to make things simple, not difficult.
It is a common mistake for starting grad students to think that their work is too simple. For that reason they will not mention known things (like explaining that ML decoding for the erasure channel consists of solving linear equations, because they fear this is too simple and well known).
Always mention the basic foundations while you try to explain something non-trivial. Your goal is not to sound smart but rather to have your audience walk out knowing something more.
Even when your audience hears things they already know, they get a warm fuzzy feeling, they do not think you are dumb.
5. Add redundancy, repeat a lot in words.
Do not say ‘We try to minimize d(k)’.
Say `we try to minimize the degree d which as I mentioned, is a function of the number of symbols k’. Repeat things all the time: Summarize what you will talk about, and in conclusions say the main points again.
6. Go back to basic concepts in words, repeat definitions.
Try to mention the basic mathematical components not the jargon you have introduced. Do not not say ‘Therefore, the code is MSR-optimal‘ but ‘Therefore, the code minimizes the repair communication (what we call MSR optimal)‘. Try to reduce your statements back to fundamental things like probabilities, graphs, rank of matrices, etc whenever possible. Do not just define some alpha jargon in the first slide and talk about that damn alpha throughout your talk.
7. Never go over time.
I have often seen even experienced speakers getting a warning that they have 3 minutes and still trying to go through their ten last slides. When you are running out of time, the goal is not to talk faster.
Say something like ‘Unfortunately or fortunately for you, I do not have time to go into the proof so I will have to skip it. The main ingredient involves analyzing random matchings which is done through Hall’s theorem and union bounds. Please talk to me offline if you are interested…”
Then, go through your conclusions slowly, repeating your main points.
This is another example of multi-resolution: you explain the techniques at a high level first. Even if you had time, you would still first have to give a one sentence high level description and then get into the the details.
8. Draw attention to important slides.
People are probably checking the Euro final when you are at slide 4, explaining what your problem is all about. Wake them up and give a notification that this is the one slide they do not want to miss. Do this right before the critical points.
9. Every slide should have one simple message.
After you make your slides ask yourself: what is the goal of this slide, I just want to explain this part. Iteratively try to simplify your slides into smaller and smaller messages. It is easier for your audience to grasp one packet of information at a time. Do not have derivations on slides (especially for an 18 minute talk), unless there is one very simple trick you really want to show. Showing math does not make you look smarter.
10. Be minimalist.
Every word on your slides, every symbol or equation you put up there dilutes the attention of your audience. Look at each bullet/slide and ask, do I really need this part or can I remove it?
11. Be excited.
Vary the tone of your voice, it may wake up somebody. You need to entertain and perform. Think: if you are not excited with your results why should anybody else be?
12. Cite people.
When somebody has related prior work, cite them on your slide. That has the benefit of waking them up when they see or hear their name.
As Rota says: `Everyone in the audience has come to listen to your lecture with the secret hope of hearing their work mentioned.‘
13. Connect to what your audience cares about.
This is non-trivial and requires experience. If you are giving a talk in a fountain codes session, you do not have to spend ten minutes defining things your audience knows already. Still define it quickly to make sure everybody is on the same page on notation. Knowing how to be at the right resolution for your audience becomes easier in time.
14. Prepare your logistics.
Know the room (go there before), know who your session chair is, have your macbook projector dongle, pre-load your slides on a USB. Bring your charger, disconnect from the internet (fun Skype messages pop-up during talks). If you are using a different machine, test your Powerpoint slides (hint: they look completely different).
15. Talk to people afterwards.
Talk to people about their work and your work. Remember that this is a professional networking event. Do not hang out with your friends, you have plenty of time for that after you go back home. Networking with other students and faculty is very important, in my case I learn more by talking to people offline than in talks.
16. Engineering theory is essentially story-telling.
Our papers and talks are essentially story-telling: Here is a model for a wireless channel, here is a proof about this model. A good story has an intellectual message that will hopefully help people think about a real engineering problem in a cleaner way.
The other aspect of our job is creating algorithms that are hopefully useful in real systems. Think: what is your story and how will you present it in your talk.
17. Read the brilliant Ten Lessons I Wish I Had Been Taught by Gian-Carlo Rota.
I didn’t do such a great job of taking notes this time, but I went to a number of talks today. Maybe Max will blog too.
If you’re attending ISIT then you probably got an email about Trailhead, a graphical system which links papers at ISIT “based on how many authors they have in common in the references, and each paper is linked to the 4 closest neighbors.” It’s written by Jonas Arnfred, a student at EPFL. The search feature doesn’t seem to be working, but it’s a fun little app.
I wonder how different the graph would look using something like the Toronto Paper Matching System, which is used by NIPS and ICML to match papers to reviewers. One could even imagine a profiler which would help you pick out papers which would be interesting to you — you could upload 10 papers of your own or that you find interesting, and it could re-visualize the conference through that viewpoint.
I was interested in the 19 papers which had no connections. Here are a few, randomly sampled:
 -Additive Self-Dual Codes Preserving Their Properties
-Additive Self-Dual Codes Preserving Their PropertiesThey seem to run the gamut, topic wise, but I think one would be hard-pressed to find many unlinked multi-user information theory papers.
On the other side, there’s a little cluster of quantum information theory papers which all have similar citations, unsurprisingly. They show up as a little clique-ish thing on the bottom right in my rendering (it may be random).
Who are my neighbors in the graph?
On Saturday I attended the Electronic Data Methods (EDM) Forum Symposium in Orlando. The focus of the workshop was how to build infrastructure for sharing clinical data for improving patient care. This comes in two flavors : quality improvement (QI), which refers to learning from clinical data much like a feedback loop, patient-centered outcomes research (PCOR) or comparative effectiveness research (CER), which is looks at how patient outcomes vary across different treatments. There’s a lot of hope that moving to electronic health records (EHRs) can facilitate these kind of studies, but the upshot of the workshop was that there are a lot of practical impediments.
One big issue that came up was essentially how EHRs are used, and how the data in them is hard to get out in a consistent and quantifiable way. Physicians record results in idiosyncratic ways, and in order to get practicing physicians to buy-in, the data format of EHRs is rather flexible, resulting in huge headaches for people trying to extract a data table out of a databased of EHRs. Much of the data is in running text — NLP approaches are improving, but it’s far from automated.
Once the data is extracted, it turns out it’s quite noisy, and poorly validated. Sometimes it’s a case of garbage-in : the data was not recorded properly in the first place. Other times, it’s due to miscalibration. There were a number of talks (which I missed) dedicated to this. Then there are questions of whether the data you have collected is representative. If you are trying to draw inferences across multiple sites, how do we appropriately account for confounding factors such as demographic differences? This is the kind of thing that can plague even a single-site observational study, butit becomes particularly acute for multi-site investigations.
Finally, even if each site can extract a more-or-less clean data set, you have the problem of sharing this data. This raises headaches from a policy perspective as well as technological perspective. On the policy side, each site has its own IRB and own review, and many instituions are hesitant to cede authority to third party or federated IRBs. For a small number of sites, a policy and technology framework can be worked out, but scaling these systems up and providing oversight is going to raise new challenges that we probably cannot anticipate. Even if two sites want to share data, they have to implement privacy protections, and depending on the kind of data being shared, technologies may not even exist to mask patient identities — biological samples are inherently problematic in this regard, but even sharing a data table is non-trivial. Apart from the privacy concerns, creating a common schema for the data to be shared sounds like an obvious thing to do, but if the two sites are using different EHR software… well, let’s say it’s not as easy as sharing PowerPoint from Mac to PC.
All in all, I came away feeling like the state of the art is both depressing and invigorating — there’s a lot to do, and I just hope that the short time frame that people go on about doesn’t result in half-baked partial solutions becoming the standard. There are a lot of questions from basic statistics through distributed system design here, so maybe after chewing on it a while I’ll get some new problem ideas.
