My department at Rutgers, like many engineering departments across the country, has a somewhat sizable Master’s program, mostly because it “makes money” for the department [1]. The vast majority of the students in the program are international students, many of whom have English as a second or third language, and whose undergraduate instruction was not necessarily in English. As a consequence, they face considerable challenges in writing in general, and academic writing in particular. Faced with the prospect of writing an introduction to a project report and wanting to sound impressive or sophisticated, many seem tempted into copying sentences or even paragraphs from references without citation. This is, of course, plagiarism, and what distresses me and many colleagues is that the students often don’t understand what they did wrong or how to write appropriately in an academic setting. Is this because most non-American universities don’t teach about referencing, citation, and plagiarism? I hesitate to lay the blame elsewhere — it’s hard (initially) to write formally in a foreign language. However, the students I have met say things like “oh, I thought you didn’t need to reference tutorials,” so there is definitely an element of ill-preparedness. Adding to this of course is that students are stressed, find it expedient, and hope that nobody will notice.
Most undergrad programs in the US have some sort of composition requirement, and at least at my high school, we learned basic MLA citation rules as part of English senior year. However, without assuming this background/pre-req, what can we do? My colleague Waheed Bajwa was asking if there are additional resources out there to help students learn about plagiarism before they turn in their assignments. Of course we put links to resources in syllabi, but as we all know, students tend to not read the syllabus, especially what seem like administrative and legalistic things. Academic misconduct is serious and can result in expulsion, but unless you’re a vindictive type, the goal shouldn’t be to have a “one strike and you’re out” policy. I’ve heard someone else suggest that students sign a contract at the beginning of the semester so they are forced to read it. Then, if they are given an automatic F for the class you can point to the policy. That also seems like dodging the underlying issue, pedagogically speaking.
Another strategy I have tried is to have students turn in a draft of a final project, which I then run through TurnItIn [2] or I manually search for copied sentences. I then issue a stern/threatening warning with links to information about plagiarism. Waheed does the same thing, but this is pretty time-intensive and also means that some students get the attention and some don’t. Students who are here for a Masters lack some incentives to do the right thing the first time — if this is the last semester of their program and suddenly this whole plagiarism thing rears its head in their last class, they may be tempted to just fix the issues raised in the draft and move on without really internalizing the ethics. I’m not saying students are unethical. However, part of engineering/academics, especially at the graduate level, is teaching the ethics around citation and attribution. I pointed out to one student that copying from sources without attribution is stealing and that kind of behavior could get them fired at a company, especially if they violate a law. They seemed surprised by this metaphor. That’s just an anecdote, but I find it telling.
The major issues I see are that:
- Undergrad-focused models for plagiarism education do not seem to address the issue of ESL-writers or the particulars of scientific/engineering writing.
- Educating short-term graduate students (M.S.) about plagiarism in classes alone results in uneven learning and outcomes.
What we (and I think most programs) really need is an earlier and better educational intervention that helps address the particulars of these programs. I was Googling around for possible solutions and came across a paper by Gunnarsson, Kulesza, and Pettersson on “Teaching International Students How to Avoid Plagiarism: Librarians and Faculty in Collaboration”:
This paper presents how a plagiarism component has been integrated in a Research Methodology course for Engineering Master students at Blekinge Institute of Technology, Sweden. The plagiarism issue was approached from an educational perspective, rather than a punitive. The course director and librarians developed this part of the course in close collaboration. One part of the course is dedicated to how to cite, paraphrase and reference, while another part stresses the legal and ethical aspects of research. Currently, the majority of the students are international, which means there are intercultural and language aspects to consider. In order to evaluate our approach to teaching about plagiarism, we conducted a survey. The results of the survey indicate a need for education on how to cite and reference properly in order to avoid plagiarism, a result which is also supported by students’ assignment results. Some suggestions are given for future development of the course.
This seems to be exactly the kind of thing we need. The premises of the paper are exactly as we experience in the US: reasons for plagiarism are complex, and most students plagiarize “unintentionally” in the sense that the balance between ethics and expediency is fraught. One issue the authors raise is that “views of the concept of plagiarism… may vary greatly among students from one country” so we must be “cautious about making assumptions based on students’ cultural background.” When I’ve talked to professional colleagues (in my field and in other technical fields) I often hear statements like “students from country X don’t understand plagiarism” — we have to be careful about generalizations!
The key aspect of the above intervention is partnering with librarians, who are the experts in teaching these concepts, as part of a research methods course. Many humanities programs offer field-specific research methods courses. These provide important training for academic work. We can do the same in engineering, but it would require more effort and resources. For those readers interested in the ESL issues, there are a lot of studies in the references that describe the multifaceted aspects of plagiarism, especially among international students. A major component of the authors’ proposed intervention is the Refero tutorial, which is a web course for students to take as part of the course. We can’t delegating plagiarism education to a web tutorial, but we have to start somewhere. Another resource I found was this large collection of tutorials collected by Macie Hall from Johns Hopkins, but these are focused more at US undergraduates.
Does your institution have a good anti-plagiarism orientation unit? Does it work? When and how do you provide this orientation?
[1] There is much ink to be spilled debating this claim.
[2] I have many mixed feeling about the ethics of TurnItIn, especially after discussions with others.


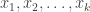

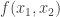







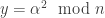

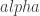

![\{ x_i : i \in [N] \}](https://s0.wp.com/latex.php?latex=%5C%7B+x_i+%3A+i+%5Cin+%5BN%5D+%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
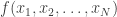
![\{y_i : i \in [N]\}](https://s0.wp.com/latex.php?latex=%5C%7By_i+%3A+i+%5Cin+%5BN%5D%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)
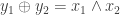

 individuals with data
individuals with data  representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction
representing some sensitive quantity are to be surveyed by an untrusted statistician. Concretely, suppose that the individual bits represent whether the person is a drug user or not. The statistician/surveyor wants to know the fraction 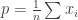 of users in the population. However, individuals don’t trust the surveyor. What to do?
of users in the population. However, individuals don’t trust the surveyor. What to do?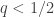 . The individual flips the coin in private. If it comes up heads, they lie and report
. The individual flips the coin in private. If it comes up heads, they lie and report  . If it comes up tails, they tell the truth
. If it comes up tails, they tell the truth  . The surveyor doesn’t see the outcome of the coin, but can compute the average of the
. The surveyor doesn’t see the outcome of the coin, but can compute the average of the  . What is the expected value of this average?
. What is the expected value of this average?![\mathbb{E}\left[ \frac{1}{n} \sum_{i=1}^{n} y_i \right] = \frac{1}{n} \sum_{i=1}^{n} (q (1 - x_i) + (1 -q) x_i) = q + (1 - 2q) p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+y_i+%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%28q+%281+-+x_i%29+%2B+%281+-q%29+x_i%29+%3D+q+%2B+%281+-+2q%29+p&bg=ffffff&fg=333333&s=0&c=20201002) .
. : if we have a reported average
: if we have a reported average  then estimate
then estimate  .
.
 , we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of
, we can see that the protocol guarantees differential privacy. This gives a possibly friendlier interpretation of  in terms of the “lying probability”
in terms of the “lying probability”  . We can plot this:
. We can plot this:
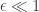 , but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case.
, but in practice this turns out to be quite difficult. Why so pessimistic? The differential privacy thread model is pretty pessimistic — it’s your plausible deniability given that everyone else in the data set has revealed their data to the surveyor “in the clear.” This is the fundamental tension in thinking about the practical implications of differential privacy — we don’t want to make conditional guarantees (“as long as everyone else is secret too”) but the price of an unconditional guarantee can be high in the worst case.