Michael Eisen gave a talk at the Commonwealth Club in San Francisco recently. Eisen is the founder of the Public Library of Science (PLoS), which publishes a large number of open-access journals in the biosciences, including the amazingly named PLoS Neglected Tropical Diseases. His remarks begin with the background on the “stranglehold existing journals have on academic publishing.” But he also has this throwaway remark:
One last bit of introduction. I am a scientist, and so, for the rest of this talk, I am going to focus on the scientific literature. But everything I will say holds equally true for other areas of scholarship.
This is simply not true — one cannot generalize from one domain of scholarship to all areas of scholarship. In fact, it is in the differences between dysfunctions of academic communication across areas that we can understand what to do about it. It’s not just that this is a lazy generalization, but rather that the as Eisen paints it, in science the journals are more or less separate from the researchers and parasitic entities. As such, there are no reasons that people should publish with academic publishers except for some kind of Stockholm syndrome.
In electrical engineering and computer science the situation is a bit different. IEEE and ACM are not just publishing conglomerates, but are supposed to be the professional societies for their respective fields. People gain professional brownie points for winning IEEE or ACM awards, they can “level up” by becoming Senior Members, and so on. Because disciplinary boundaries are a little more fluid, there are several different Transactions in which a given researcher may publish. At least on paper, IEEE and ACM are not-for-profit corporations. This is not to say that engineering researchers are not suffering from a Stockholm syndrome effect with these professional societies. It’s just that the nature of the beast is different, and when we talk about how IEEExplore or ACM Digital Library is overpriced, that critique should be coupled with one of IEEE’s policy requiring conferences to have a certain profit level. These things are related.
The second issue I had is with Eisen’s proposed solution:
There should be no journal hierarchy, only broad journals like PLOS ONE. When papers are submitted to these journals, they should be immediately made available for free online – clearly marked to indicate that they have not yet been reviewed, but there to be used by people in the field capable of deciding on their own if the work is sound and important.
So… this already exists for large portions of mathematics and mathematical sciences and engineering in the form of ArXiV. The added suggestion is a layer of peer-review on top, so maybe ArXiV plus a StackExchange thing. Perhaps this notion is a radical shift for life sciences where Science and Nature are so dominant, but what I learn myself from looking at the ArXiV RSS feed is that the first drafts of papers that get put up there are usually not the clearest exposition of the work, and without some kind of community sanction (in the form of rejection), there is little incentive for authors to actually go back and make a cleaner version of their proof. If someone has a good idea or result but a confusing presentation they are not going to get downvoted. If someone is famous they are unlikely to get downvoted.
In the end what PLoS ONE and the ArXiV-only model for publishing does is reify and retrench the existing tit-for-tat “clubbiness” that exists in smaller academic communities. In a lot of CS conferences reviewing is double-blind as a way to address this very issue. When someone says “all academic publishing has the same problems” this misses the point, because the problems is not always with publishing but with communication. We need to understand the how the way we communicate the products scholarly knowledge is broken. In some fields, I bet you could argue that papers are inefficient and bad ways of communicating results. In this sense, academic publishing and its rapacious nature are just symptoms of a larger problem.


 balls (people) and
balls (people) and  bins/categories (days), how big should
bins/categories (days), how big should 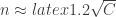 , as we know, but we can expand this to deal with approximate matches (you need only 7 people to get 2 birthdays in the same week with probability around 1/2). If you want to put a graph on it you can ask social-network coincidence questions and get some scalings as a function of the number of edges and number of categories — here there are
, as we know, but we can expand this to deal with approximate matches (you need only 7 people to get 2 birthdays in the same week with probability around 1/2). If you want to put a graph on it you can ask social-network coincidence questions and get some scalings as a function of the number of edges and number of categories — here there are  which I had found interesting:
which I had found interesting: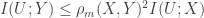 .
. , but by another quantity:
, but by another quantity:
 is given by the following definition.
is given by the following definition. and
and  be random variables with joint distribution
be random variables with joint distribution  . We define
. We define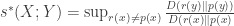 ,
, denotes the
denotes the  -marginal distribution of
-marginal distribution of  and the supremum on the right hand side is over all probability distributions
and the supremum on the right hand side is over all probability distributions 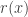 that are different from the probability distribution
that are different from the probability distribution  . If either
. If either  to be 0.
to be 0.
 have joint distribution
have joint distribution  (I know I am changing notation here but it’s easier to explain). The key to showing their result is through deriving variational characterizations of
(I know I am changing notation here but it’s easier to explain). The key to showing their result is through deriving variational characterizations of 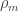 and
and 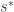 in terms of the function
in terms of the function
 , and
, and 
 ? If either
? If either 
 . However,
. However, 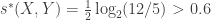 and there exists a sequence of variables
and there exists a sequence of variables  satisfying the Markov chain such that
satisfying the Markov chain such that  such that the ratio approaches
such that the ratio approaches 