This is the second part in my blogging about some of the talks I saw at ITA 2008, and also a way for me to test a tag so that readers who don’t care about information theory won’t have a huge post hogging up their aggregator window (livejournal, I’m looking at you). Again, I may have misunderstood something in the talks, so if you see something that doesn’t sound right, let me know.
Author Archives: Anand Sarwate
the bad part of the evening
Dinner was great fun, but the part where it took me almost 3 hours to get home, 2.5 of which were spent stalled in traffic to get through the detour onto the bridge was not so fun. Ironically, I decided to drive because a late dinner in the outer Richmond would have possibly meant missing the last BART and having to take the transbay bus back, but given that I got home at 3, the bus would have been faster. Plus, I could have at least read something.
I don’t understand why they don’t post a sign when you go in to the city warning you that construction will be happening that night. Furthermore, it took the cops nearly 2 hours to get out onto the streets to regulate traffic. I overheard a cop talking to a construction guy, and it seems like the cops had no idea of the duration of the construction, which is mind-boggling. Why is this whole process riddled with incompetency? Had I known it what was going to happen, I would have just skipped the whole detour thing and gone down to San Mateo and back over. I would have gotten back in time that way.
Why oh why can’t we have better managed infrastructure upgrades?
a real reprint
My dissertation committee had to be reshuffled on short notice because my outside-the-department member became inside-the-department. Luckily for me, Prof. David Blackwell kindly agreed to serve on my committee. I had a meeting with him two weeks ago, wrote up a pseudo-précis of my dissertation, and had a short chat about it and Bayesianism today. Forty-eight years ago, he wrote the first paper on the arbitrarily varying channel [1], and today he gave me an actual reprint of the article!

The staples are a little bit oxidized from time. I guess people couldn’t get rid of their reprints back then, even. QUESTA sent me reprints of my paper there and they’re just occupying space in my filing drawer. The worst part was, there was no option I could click for “no reprints — save the trees.” Of course, given my feelings about commercial publishing, I’m less likely to send a paper there in the future.
[1] D. Blackwell, L. Breiman, and A.J. Thomasian, The Capacities of Certain Channel Classes Under Random Coding, Annals of Mathematical statistics Stat. 31 (3), Sept. 1960, p.558-567.
musical epigraphs
In my ongoing quest to learn more about LaTeX than I really wanted to know, I have figured out how to use lilypond together with a redefined \chapter command. Of course, it’s all worth it because I can do this:

In other news, I’ll finish writing about ITA when I get more than 20 minutes of contiguous time.
Super Fat Tuesday
Happy Mardi Gras! And don’t forget to vote!
Africa? Where’s that?
The NY Times doesn’t bother having anything about the fighting in Chad on the front page (of the website). Instead, it has two articles about John McCain. Way go to, Gray Lady.
LaTeX instructions
To use 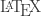
$latex x = \frac{ - b \pm \sqrt{b^2 - 4 a c} }{2 a}
then you can close it with another dollar sign:
$.
Putting it all together, the renderer will give you:
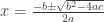
Basically, it’s like writing latex, except that every time you have to go into math mode, you have to type “latex” right after the first dollar sign.
pardon my dust
This blog is going down for a day or two (or perhaps the weekend) in order to move to a new home hosted by WordPress.com. They support LaTeX and I’ve decided to move the thing over there. It’ll take a few days for the domain redirection to catch up, so be forewarned.
The blog has now moved, and here is a test of the new embedded

Or

ITA 2008 : Part the First
I’ve spent this week at ITA 2008 at UCSD. There have been lots of great talks, but my brain is fairly saturated, so my ability to take more than cursory notes decreased as the workshop progressed. I’ve met a number of people who apparently read this blog (hi!), which is nice. One thing I’ll try to do is put in some more links to things as I think of them and also to raise some (possibly trivial) questions that came up as I wrote about the papers.
Iterative coding for network coding
Andrea Montanari, Stanford, Vishwambar Rathi, EPFL, and Rudiger Urbanke, EPFL
I think of this paper as the Shannon-theory version of the Koetter-Kschischang coding-theory analysis of network coding. There is a preprint of some of the results on ArXiV that I read a little while ago (and unsuccessfully presented in our group meeting). The channel model is a rank metric channel (see Gabidulin), and a notion of distance between subspaces can be defined. The idea is the following — messages are encoded into subspaces of a vector space over a finite field (taken to be F2 here). The set of all subspaces is the projective space, and the set of all subspaces of dimension k is the Grassmann manifold. So we can look at a codebook as a set of binary matrices of dimension m x l. In this model, headers are preserved, so the decoder in a network code knows the transfer matrix of the channel exactly. However, errors can still be introduced in the packet payload in the following sense. Each column can be written as
yj = xj + zj
where zj is uniformly chosen from an unknown subspace of limited rank. This is a perfectly good DMC channel model, and one can calculate its capacity. The interesting thing is that then you can define an LDPC code (with all variable nodes of degree 2 and a non-soliton distribution for the check nodes) across the columns of the codeword (which is a matrix, remember), with matrix-valued weights on the edges of the Tanner graph. The messages that are propagated in the BP algorithm correspond to information about affine subspace memberships of the rows. This code (a) achieves capacity on the rank metric channel, and the error for erasures also goes to 0. Since I have been concerned about jamming and interference and malicious attacks, the assumption on the header being preserved feels like a limitation of the approach, but I think that perhaps concatenating codes may also be able to preserve something about the header information. The reason I call it sort of Shannon theoretic is that the error model is random and the density evolution arguments are a bit like the probabilistic method.
On rate-distortion function of Poisson processes with a queueing distortion measure
Todd P. Coleman, UIUC, and Negar Kiyavash, UIUC, and Vijay G. Subramanian, Hamilton Institute, NUIM
The main idea here is find a rate-distortion problem corresponding to the bits through queues result on timing channels. So given a set of Poisson arrivals {Xi}, how can we define a distortion measure and rate-distortion function that makes sense? The choice they make is to requires that the reconstruction be causal, so that the packet times in the reconstructed version are delayed w.r.t. the originals and the objective then is to minimize the induced service time of the reconstruction. This makes the test channel into a first-come first-serve queue and in particular the optimal test channel is the exponential timing channel. The rate distortion function turns out to be -a log(D) where a is the intensity of the Poisson process. The benefit of their definition is that the proofs look as clean as the AWGN and BSC rate distortion proofs.
Network tomography via network coding
G. Sharma, IIT Bombay, S. Jaggi, CUHK, and B. K. Dey IIT Bombay
Network tomography means using input-output probing of a network to infer internal structural properties. In their model, all nodes have unique IDs and share some common randomness. Inferring the presence of absence of a single edge in the graph is relatively easy, and then the process can be repeated for every edge. The more interesting problem is structural inference in an adversarial setting. They show that the graph can be recovered if the min-cut from the source to destination is greater than twice the min-cut from the adversary to the destination (I think), which squares with the Byzantine Generals problem. The tomography problem is interesting, and I wonder if one can also embed adversary-detection methods as well to create a protocol to quarantine misbehaving internal nodes.
Coding theory in projective spaces
Tuvi Etzion, Technion, and Alexander Vardy, UCSD
This talk also dealt with the rank-metric channel. Previous work of Koetter and Kscischang had found analogues to the Singleton and Johnson bounds, and here they find Delsarte, Iterated Johnson, and packing bounds, as well as a “linear programming bound.” They show there are no nontrivial perfect codes in the projective space of dimension n over Fq, and define the notion of a quasilinear code, which is an abelian group in the projective space. A code is quasilinear iff the size is a power of two. Honestly, I found myself a bit lost, since I’m not really a coding theorist, but it seems that the rank metric channel has lots of interesting properties, some of which are old, and some of which are new, and so exciting new algebraic codes can be constructed for them.
On capacity scaling in arbitrary wireless networks
Urs Niesen, MIT, Piyush Gupta, Bell Labs, and Devavrat Shah, MIT
The goal for this paper was to relax some of the random-placement assumptions made in a lot of cooperative schemes for large wireless networks. They look at n nodes scattered in [0, n1/2]2 with a standard path loss model for the gains, full CSI, and equal rate demands for the each source-destination pair. There are three schemes we can consider — multihop, hierarchical cooperation, and a new scheme they have here, cooperative multihop. For large path loss exponent the multihop strategy is optimal, and in other regimes hierarchical cooperation is optimal. The cooperative multihop scheme works by dividing the network into squarelets and then doing multihop on the squarelet-level overlay graph. This strategy is optimal in some cases, and has the benefit of not relying on the node placement model, unlike the hierarchical cooperation scheme. These network models are interesting, but the full CSI assumption seems pretty darn restrictive. I wonder if the cooperative multihop would be more attractive also because channel estimation and ranging need only be done on a local level.
Percolation processes and wireless network resilience
Zhenning Kong and Edmund M. Yeh, Yale
Consider a random geometric graph with density chosen above the percolation threshold. This is an often (ab?)used model for wireless sensor networks. First off, throwing n points in the unit square converges, in distribution to the percolation model with an infinite Poisson process in the plane and the Gilbert disc model. If we make nodes “fail” by flipping a coin for each node, this is just thinning the process, so it’s easy to find a threshold on the failure probability in terms of the percolation threshold that guarantees a giant connected component will still exist. So far so good, but what happens if the failure probability depends on the degree of the node? High degree nodes may serve more traffic and hence will fail sooner, so this is a good model. This work finds necessary and sufficient conditions on the failure probability distribution p(k) for a giant connected component to still exist. Here k is the node degree. The necessary and sufficient conditions don’t match, but they are interesting. In particular, the sufficient condition is very clean. One application of these results is to a cascading failures model, where you want to stop one node going down from taking down the whole network (c.f. power failures in August 1996). It would be interesting to see if a real load redistribution could be integrated into this — nodes have weights (load) on them, proportional to degree, say, and then dynamically nodes are killed and push their load on to their ex-neighbors. How fast does the whole network collapse? Or perhaps a sleeping-waking model where a node dumps its traffic on neighbors while sleeping and then picks up the slack when it wakes up again…
The FCC and buttocks
I get the FCC’s daily email updates, which mostly contain links to boring procedural documents, but occasionally are a source of amusement. They decided to fine [pdf] ABC for the Feb. 25, 2003 episode of NYPD Blue in which a woman’s buttocks are shown. On pages 4-5, they state:
As an initial matter, we find that the programming at issue is within the scope of our indecency definition because it depicts sexual organs and excretory organs – specifically an adult woman’s buttocks. Although ABC argues, without citing any
authority, that the buttocks are not a sexual organ, we reject this argument, which runs counter to both case law and common sense.
I remember that episode causing a bit of an uproar at the time, but it took almost 5 years for this decision to come out, so I suppose they have been thinking really hard about butts over at the FCC. Perhaps they are getting a bit obsessed.
UPDATE : Language Log has more.
