Research often takes twisty little paths, and as the result of a recent attempt to gain understanding about a problem I was trying to understand the difference between the following two systems with 

- Synchronous: take all of the top balls in each bin and reassign them randomly and uniformly to the bottoms of the bins.
- Asynchronous: pick a random bin, take the top ball in that bin, and reassign it randomly and uniformly to the bottom of a bin.
These processes sound a bit similar, right? The first one is a batch version of the second one. Sort of. We can think of this as modeling customers (balls) in queues (bins) or balls being juggled by
Each of these processes can be modeled as a Markov chain on the vector of bin occupation numbers. For example, for 3 balls and 3 bins we have configurations that look like (3,0,0) and its permutations, (2,1,0) and its permutations, and (1,1,1) for a total of 10 states. If you look at the two Markov chains, they are different, and it turns out they have different stationary distributions, even. Why is that? The asynchronous chain is reversible and all transitions are symmetric. The synchronous one is not reversible.
One question is if there is a limiting sense in which these are similar — can the synchronous batch-recirculating scheme be approximated by the asynchronous version if we let
 starts with a value
starts with a value  . At each time, a random node broadcasts its value to its neighbors in the graph and they each update their value with the weighted average of their current value and the received value. Eventually, this process converges almost surely and all nodes
. At each time, a random node broadcasts its value to its neighbors in the graph and they each update their value with the weighted average of their current value and the received value. Eventually, this process converges almost surely and all nodes 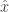 . However, in general
. However, in general  , where
, where 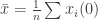 , but
, but ![\mathbb{E}[\hat{x}] = \bar{x}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Chat%7Bx%7D%5D+%3D+%5Cbar%7Bx%7D&bg=ffffff&fg=333333&s=0&c=20201002) . So this process achieves consensus but only computes the average in expectation.
. So this process achieves consensus but only computes the average in expectation. to track the effect of the broadcast. These have been studied before, but in this paper they set the initial values
to track the effect of the broadcast. These have been studied before, but in this paper they set the initial values 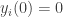 and perform updates as follows : if node
and perform updates as follows : if node  and node
and node  is a neighbor, then
is a neighbor, then

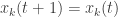

 . Each time it receives a broadcast it accumulates an offset in
. Each time it receives a broadcast it accumulates an offset in 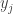 . The actual value estimate at the nodes is weighted average of the current and received value plus some of the local offset.
. The actual value estimate at the nodes is weighted average of the current and received value plus some of the local offset. and
and  and per-node matrices
and per-node matrices  . Let
. Let

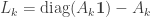

![W_k \left[ \begin{array}{cc} I - L_k & \epsilon D_k \\ L_k & S_k - \epsilon D_k \end{array} \right]](https://s0.wp.com/latex.php?latex=W_k+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+-+L_k+%26+%5Cepsilon+D_k+%5C%5C+L_k+%26+S_k+-+%5Cepsilon+D_k+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![\left[ \begin{array}{c} \mathbf{x}(t+1) \\ \mathbf{y}(t+1) \end{array} \right]^T = W(t) \left[ \begin{array}{c} \mathbf{x}(t) \\ \mathbf{y}(t) \end{array} \right]^T](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%2B1%29+%5C%5C+%5Cmathbf%7By%7D%28t%2B1%29+%5Cend%7Barray%7D+%5Cright%5D%5ET+%3D+W%28t%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%29+%5C%5C+%5Cmathbf%7By%7D%28t%29+%5Cend%7Barray%7D+%5Cright%5D%5ET&bg=ffffff&fg=333333&s=0&c=20201002)
 if node
if node  small enough, then
small enough, then ![\lim_{t \to \infty} \mathbb{E}[ \mathbf{x}(t) | \mathbf{x}(0) ] = \hat{x} \mathbf{1}](https://s0.wp.com/latex.php?latex=%5Clim_%7Bt+%5Cto+%5Cinfty%7D+%5Cmathbb%7BE%7D%5B+%5Cmathbf%7Bx%7D%28t%29+%7C+%5Cmathbf%7Bx%7D%280%29+%5D+%3D+%5Chat%7Bx%7D+%5Cmathbf%7B1%7D&bg=ffffff&fg=333333&s=0&c=20201002) and
and  under more conditions.
under more conditions. seems to buy a lot in terms of controlling bad sample paths for the process.
seems to buy a lot in terms of controlling bad sample paths for the process.