I think this is the end of my ITA blogging! But there were some issues that came up during the conference that may be of interest to some of the readers of this blog (although from anecdotal reports, there are many people who read but never comment, so I’m not sure what to do to encourage more discussions).
Networking Data Centers Randomly
Ankit Singla, Chi-Yao Hong, Brighten Godfrey, Alexandra Kolla, Lucian Popa
Brighten talked about using random graphs as a network topology for the interconnections within a data center. Intra-center traffic is exploding and the current hierarchical back-end topology is not very efficient. They propose wiring servers together using an expander graph and show that the resulting network has better throughput and us easier to incrementally expand. There are, of course, some physical issues (what about the spaghetti of cables?) but this approach seems quite promising.
Universal Outlier Detection
Sirin Nitinawarat, Yun Li, Venugopal Veeravalli
The “universal outlier detection” problem can be phrased as follows. Suppose we have two distributions, 




On Stochastic Subgradient Mirror-Descent Algorithm with Weighted Averaging
Angelia Nedich
In mirror descent or other stochastic approximation-based optimization algorithms, sometimes taking the average of the iterates (or just the tail) can lead to better estimates because the randomness can get averaged out. The goal in this work was to produce algorithms which lead to more favorable tail-averaged estimates. To do this, we should really modify the algorithm itself and change the weight sequence. An open question is if the great convergence rates that they get are only in theory but also appear in implementations.
Alternating Minimization for Low-rank Recovery – Provable Guarantees
Sujay Sanghavi
Sujay talked about replacing a minimization like 

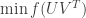


Self-concordant scale estimation for manifold learning
Dominique Perrault-Joncas, Marina Meilă
Marina Meilă gave a talk about manifold learning, or the learning of low-dimensional (nonlinear) structures in higher dimensional space. Many methods use some sort of mesh on the given data points and use the graph Laplacian. The underlying differential geometry view is that there is a Riemannian metric 

I enjoy(ed) reading everyone of your ITA blog posts. Thanks! I would love to know more about the last 2 days that I didn’t attend.
I would too, but I somehow lost steam on my note-taking by then :-/ Plus I had to leave on Friday after lunch basically.