I have been reading Ahlswede’s paper on An Elementary Proof of the Strong Converse Theorem for the Multiple-access Channel, J. Combinatorics, Information and System Sciences, Vol. 7, No. 3, 216-230. The preprint is here but I have a scanned version of the journal version thanks to the intrepid UC Libraries staff — they are a great resource!
I’m going to split up this rather rambling post into a few posts. The main result is the following: for the discrete memoryless MAC, let
Then the for any code of blocklength 


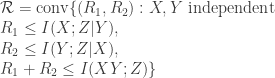

The first step in the proof is to look at non-stationary discrete memoryless channels. Suppose we have a codebook for a point-to-point channel 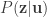
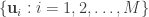



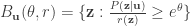
The first thing to show is a packing lemma.
Lemma. Suppose that for an code with
codewords and maximal error
and positive numbers
such that
.
Then

This Lemma can be used, with an appropriate choice of

The first question is what 
Ahlswede calls this the “Fano-distribution,” and remarks that you can use this to get a weak converse. A good choice, used by Augustin, is to pick the output distribution induced by the product of the marginal distributions on each input letter via the uniform distribution of the codebook. Phew! That is a mouthful. So first you take the marginal distribution on each letter of the input:
then take the product of these:
And then look at the corresponding output distribution:
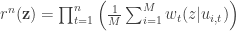
Ahlswede calls the input distribution in this case the “Fano*-distribution.” The intuition about this choice is that it factors into independent components (so we can split things into a sum of mutual informations), but the distribution is still related to the codebook rather than just the channel.


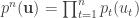
The next thing is to choose an appropriate 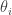





So we treat 
![\theta_i = \mathbb{E}[ A_i ] + ( \frac{2}{1 - \lambda} \mathrm{Var}[A_i] )^{1/2}](https://s0.wp.com/latex.php?latex=%5Ctheta_i+%3D+%5Cmathbb%7BE%7D%5B+A_i+%5D+%2B+%28+%5Cfrac%7B2%7D%7B1+-+%5Clambda%7D+%5Cmathrm%7BVar%7D%5BA_i%5D+%29%5E%7B1%2F2%7D&bg=ffffff&fg=333333&s=0&c=20201002)
With this choice we can just apply Chebyshev’s inequality to get that 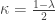

Applying the Lemma and indulging in some bounding-ology yields the point-to-point result.
For a code of blocklength
,
where the distributions of the random variables are given by the Fano-distribution on the codewords.
Note that in the mutual information expressions we use the Fano-distribution on the codewords. The choice of the Fano*-distribution for 

Great topic for a writeup Anand! One thing that always made me uncomfortable about results like the lemma here and others in Csiszar & Korner: what’s the intuition (or even the technical reason) for the $1 – \lambda – \kappa$?
Also, interesting how this result for non-stationary DMCs connects to the information-spectrum work 20 years later. The idea of using this Fano*-distribution was something interesting that I saw first in the information-spectrum stuff.
Ha! I knew you would find it interesting. More comments later…
The shows up in the proof where you look at the part of the decoding set
shows up in the proof where you look at the part of the decoding set  for message
for message  that is not part of the
that is not part of the  set defined above. Since the probability of successful decoding is
set defined above. Since the probability of successful decoding is 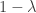 , the probability of getting an output that is in
, the probability of getting an output that is in  but not in
but not in 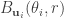 is at least
is at least  .
.
We want to get a lower bound on the mass of such outputs under the distribution.
distribution.
Nice post! There are some things I can’t understand about that paper. But I’ll wait for the next posts, in case they are answered there. :)
Ah but you will have to wait a few days for that — I keep saying I’m going to do it but then I get lazy…
Pingback: A unified converse for noiseless and noisy channel codes « The Information Structuralist
Pingback: The strong converse for the MAC, part 4 « An Ergodic Walk
Pingback: The strong converse for the MAC summary « An Ergodic Walk