I am reading this nice paper by Harsha et al on The Communication Complexity of Correlation and some of their results rely on the following cute lemma (slightly reworded).
Let
and
be two distributions on a finite set
such that the KL-divergence
. Then there exists a sampling procedure which, when given a sequence of samples
drawn i.i.d. according to
such that the sample
is distributed according to the distribution
where the expectation is taken over the sample sequence and the internal randomness of the procedure.

So what is the procedure? It’s a rejection sampler that does the following. First set 
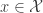


- Output
with probability
.
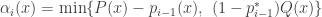



Ok, so what is going on here? It turns out that 

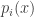




What we want then is that 




In order to show that the sampling is correct, i.e. that the output distribution is 
![\mathbb{E}[ \log i^{\ast} ] \le D(P \| Q) + O(1)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%5Clog+i%5E%7B%5Cast%7D+%5D+%5Cle+D%28P+%5C%7C+Q%29+%2B+O%281%29&bg=ffffff&fg=333333&s=0&c=20201002)
This is an interesting little fact on its own. It comes out because
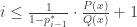
and then expanding out ![\mathbb{E}[ \log i^{\ast} ] = \sum_{x} \sum_{i} \alpha_i(x) \cdot \log i](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B+%5Clog+i%5E%7B%5Cast%7D+%5D+%3D+%5Csum_%7Bx%7D+%5Csum_%7Bi%7D+%5Calpha_i%28x%29+%5Ccdot+%5Clog+i&bg=ffffff&fg=333333&s=0&c=20201002)
One example application of this Lemma in the paper is the following problem of simulation. Suppose Alice and Bob share an unlimited amount of common randomness. Alice has some 





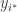
![\mathbb{E}_{P(x)}[ D( P(y|x) \| P(y) ) + 2 \log( D( P(y|x) \| P(y) ) + 1) + O(1) ]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7BP%28x%29%7D%5B+D%28+P%28y%7Cx%29+%5C%7C+P%28y%29+%29+%2B+2+%5Clog%28+D%28+P%28y%7Cx%29+%5C%7C+P%28y%29+%29+%2B+1%29+%2B+O%281%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
which, after some love from Jensen’s inequality, turns out to be upper bounded by
![I(X ; Y) + 2 \log( I(X; Y) + 1) + O(1) ]](https://s0.wp.com/latex.php?latex=I%28X+%3B+Y%29+%2B+2+%5Clog%28+I%28X%3B+Y%29+%2B+1%29+%2B+O%281%29+%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Pretty cute, eh?
