I had already written most of this, but was waiting to write up a few thoughts on other talks. Then a week or two turned into a month plus, so… I’ll just post these few and give up on the rest (sorry!) due to time issues.
High-resolution functional quantization
Vinith Misra, Vivek K Goyal, and Lav R. Varshney, MIT
This talk was on distributed quantization, where one encoder observes 

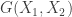

Unequal error protection: some fundamental limits and optimal strategies
Shashi Borade, Baris Nakiboglu, Lizhong Zheng (MIT)
This was a really interesting talk as part of the “graduation day” series — the idea is to do unequal error protection (UEP) message-wise (as opposed to bit-wise). It may be desirable to reserve a few “special messages” and guarantee them special error protection. To quantify this distinction, we can require the error exponent on those messages to be larger. Does this affect the rate? The picture to think about is a bucket being filled with “boulders” of special codewords and “gravel” for regular codewords. Although bit-wise UEP is hard, message-wise UEP is possible, and indeed you can have many priority levels for your protected messages. When feedback is added, bitwise protection is also possible.
Sequential compressed sensing
Dmitry Malioutov, Sujay Sanghavi, MIT, and Alan Willsky
This talk was on the compressed sensing problem in a feedback setting — the compressor takes random projections and sends them to a decoder, which uses a feedback link to terminate the compression when it is ready. Sujay presented some results on how to choose a good stopping rule for the decoder based on a criterion like “the answer should not have changed in the last T steps. These bounds take the form of confidence intervals. It seemed like an interesting problem, especially in the context of sequential learning algorithms.
An information-theoretic derivation of graph partitioning
Chris Wiggins, Columbia
This talk uses information theoretic measures to justify different ad-hoc measures that have been proposed for spectral graph partitioning. The connection comes via a random walk story wherein the objective is to find the partition that minimizes the information loss between the starting and ending points of a random walk on the graph. Two other algorithms, normalized and average cuts, can be shown to have an interpretation within this framework. I liked this talk quite a bit, but because the slides were so clear I ended up taking fewer notes and so now I can’t remember as much of it as I wanted.
Combining geometry and combinatorics: A unified approach to sparse signal recovery
A.C. Gilbert, University of Michigan, P. Indyk, H. Karloff, M.J. Strauss
This work provided some combinatorial constructions with uniform guarantees for sparse signal recovery. The main tool they use are projection matrices based on expander graphs, which satisfy the restricted isometry property (RIP) but only for certain p-norms (in particular, not for 
Learning mixtures of distributions using correlations and independence
Kamalika Chaudhuri, UCSD, and Satish Rao, UC Berkeley
Suppose your data comes from a mixture of Gaussians. If the centers of the mixture elements are well-separated then you can take an SVD and may recover the centers. However, if the covariances in your mixture components have a high variance component orthogonal to the dimension in which the centers differ, then you may miss out when you do the SVD. In this paper Kamalika suggested a new algorithm which splits the coordinates of the data and does some cross-covariances. This method works under a less restrictive separation condition than other methods.
Declaring independence via the sketching of sketches
Piotr Indyk, MIT, and Andrew McGregor, UCSD
I was vaguely familiar with the sketching problem for databases before going to this talk, but it was clear after it that I didn’t really know how sketches work. The problem addressed in this paper is relatively simple to state — your algorithm can make one pass on a set of data pairs 



it’s sad how i understand more of your work posts now. i guess i’m not as immune to grad school as i thought.
Hurray Anna Gilbert and Martin Strauss!