Perfect Recovery and Sensitivity Analysis of Time Encoded Bandlimited Signals
Aurel A. Lazar and László T. Tóth
IEEE Transactions on Circuits and Systems – I: Regular Papers, vol. 51, no. 10, October 2004
I heard about this paper from Prakash Narayan, who came to give a seminar at last semester, and I thought it was pretty interesting. In an undergrad signals and systems class we usually spend most of our time talking about converting an analog signal x(t) into a discrete-time signal x[n] by sampling x(t) regularly in time. That is, we set x[n] = x(nT) for some sampling interval T. There are at least two reasons for doing things this way: it’s simple to explain and the math is beautiful. If x(t) is a bandlimited signal, it’s Fourier transform has support only on the interval [-B,B], and the famous Nyquist–Shannon sampling theorem (which goes by many other names) tells us that if 1/T > 2 B the original signal x(t) is recoverable from the sequence x[n]. Since there is all of this beautiful Fourier theory around we can convolve things and show fun properties about linear time-invariant systems with the greatest of ease.
So far so good. But sampling is only half the story in Analog to Digital conversion. Not only should the times be discretized, but the values should also be discretized. In this case we need to use a quantizer on the samples x[n]. Fast, high precision quantizers are expensive, especially at low power. On the other hand, clocks are pretty cheap. The suggestion in this paper is to think about time-encoding mechanisms (TEMs), in which we encode a bandlimited x(t) into a sequence of times {tk}. Another way to think about it is as a signal z(t) taking values +b or -b and switching values at the times {tk}. The disadvantage of this representation is that linear operations on analog signals don’t turn into linear operations on the discrete signals. However, this conversion can be implemented with an adder, integrator, and a noninverting Schmitt trigger that detects when the output of the integrator passes a threshold.
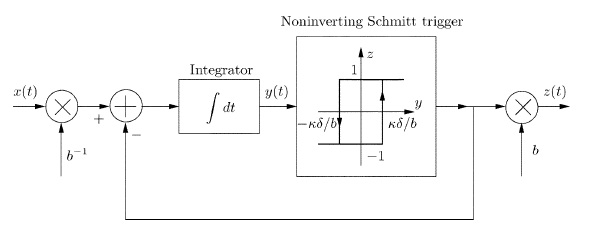
This paper shows that the circuit above can be implemented in real time and that {tk} are sufficient to reconstruct x(t). The recovery algorithm looks pretty simple — multiplication by a certain pseudoinverse matrix. The second part of the paper deals with the stability of the system with respect to errors in the decoder parameter or time quantization. The compare the scheme to irregular sampling algorithms. The tools they use for this analysis come from non-harmonic analysis, but the math isn’t all that rough.
This work is different than the sampling with a finite rate of innovation work of Vetterli, Marziliano, and Blu, which says (loosely) that regular sampling is good for a wider class of signals than bandlimited signals. It would be interesting to see if a TEM mechanism is good for those signals as well. That might be another robustness issue to explore.
Finally, one interesting connection (and possible another motivation for this work) is that neurons may be doing this kind of time encoding all the time. The integrate-and-fire model of a neuron is, from a black-box perspective, converting an input signal into a sequence of times, just like a TEM.
