I didn’t do such a great job of taking notes this time, but I went to a number of talks today. Maybe Max will blog too.
Tag Archives: information theory
Quick thoughts on Trailhead
If you’re attending ISIT then you probably got an email about Trailhead, a graphical system which links papers at ISIT “based on how many authors they have in common in the references, and each paper is linked to the 4 closest neighbors.” It’s written by Jonas Arnfred, a student at EPFL. The search feature doesn’t seem to be working, but it’s a fun little app.
I wonder how different the graph would look using something like the Toronto Paper Matching System, which is used by NIPS and ICML to match papers to reviewers. One could even imagine a profiler which would help you pick out papers which would be interesting to you — you could upload 10 papers of your own or that you find interesting, and it could re-visualize the conference through that viewpoint.
I was interested in the 19 papers which had no connections. Here are a few, randomly sampled:
- Fish et al., Delay-Doppler Channel Estimation with Almost Linear Complexity
- Song and İs ̧can, Network Coding for the Broadcast Rayleigh Fading Channel with Feedback
- Bilal et al., Extensions of
-Additive Self-Dual Codes Preserving Their Properties
- Bernal-Buitrago and Simón, Partial Permutation Decoding for Abelian Codes
- Kovalev and Pryadko, Improved quantum hypergraph-product LDPC codes
- Price and Woodruff, Applications of the Shannon-Hartley Theorem to Data Streams and Sparse Recovery
- Willems, Constrained Probability
- Nowak and Kays, On Matching Short LDPC Codes with Spectrally-Efficient Modulation
They seem to run the gamut, topic wise, but I think one would be hard-pressed to find many unlinked multi-user information theory papers.
On the other side, there’s a little cluster of quantum information theory papers which all have similar citations, unsurprisingly. They show up as a little clique-ish thing on the bottom right in my rendering (it may be random).
Who are my neighbors in the graph?
- Strong Secrecy in Compound Broadcast Channels with Confidential Messages — Rafael F. Wyrembelski, Holger Boche
- Lossy Source-Channel Communication over a Phase-Incoherent Interference Relay Channel — H. Ebrahimzadeh Saffar, M. Badiei Khuzani and P. Mitran
- Shannon Entropy Convergence Results in the Countable Infinite Case — Jorge Silva, Patricio Parada
- Non-adaptive Group Testing: Explicit bounds and novel algorithms — Chun Lam Chan, Sidharth Jaggi, Venkatesh Saligrama, Samar Agnihotri
- Non-coherent Network Coding: An Arbitrarily Varying Channel Approach — Mahdi Jafari Siavoshani, Shenghao Yang, Raymond Yeung
The Matrix Determinant Lemma
I had never really heard of this result, sometimes called the Matrix Determinant Lemma, but it came up in the process of answering a relatively simple question. Suppose I have an 


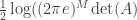


On the face of it, this seems intuitively easy — diagonalize
Matrix Determinant Lemma. Let
positive definite matrix and
and
be two
matrices. Then
.
To see this, note that
![\left[ \begin{array}{cc} A & -U \\ V^{H} & I \end{array} \right] = \left[ \begin{array}{cc} A & 0 \\ V^{H} & I \end{array} \right] \cdot \left[ \begin{array}{cc} I & - A^{-1} U \\ 0 & I + V^H A^{-1} U \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A+%26+-U+%5C%5C+V%5E%7BH%7D+%26+I+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+A+%26+0+%5C%5C+V%5E%7BH%7D+%26+I+%5Cend%7Barray%7D+%5Cright%5D+%5Ccdot+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+%26+-+A%5E%7B-1%7D+U+%5C%5C+0+%26+I+%2B+V%5EH+A%5E%7B-1%7D+U+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
and take determinants on both sides.
So now applying this to our problem,
But the right side is clearly maximized by choosing 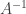
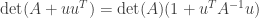
A new record for the IT Transactions?
I was walking back from a seminar today and talking to Yury Makarychev and he mentioned that he and his brother Konstantin had written a paper and submitted it to the IT Transactions more than 10 years ago on a new proof of the Gács-Körner result that common information is much less than the mutual information. They submitted it, got reviews back, submitted a revised version, and then it was lost in the aether of Pareja. Now, a decade later, it is finally available to read and will appear in a future issue.
ISIT Early Registration
Upper bounds for causal adversaries
Bikash Dey, Mike Langberg, Sid Jaggi, and I submitted an extended version of our (now accepted) ISIT paper on new upper bounds for binary channels with causal adversaries to the IT Transactions. The model is pretty straightforward : Alice (the encoder) transmits a message to Bob (the receiver) encoded over 
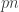

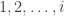
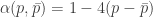
![C \le \min_{\bar{p} \in [0,p]} \left[ \alpha(p,\bar{p})\left(1-H\left(\frac{\bar{p}}{\alpha(p,\bar{p})}\right)\right) \right]](https://s0.wp.com/latex.php?latex=C+%5Cle+%5Cmin_%7B%5Cbar%7Bp%7D+%5Cin+%5B0%2Cp%5D%7D+%5Cleft%5B+%5Calpha%28p%2C%5Cbar%7Bp%7D%29%5Cleft%281-H%5Cleft%28%5Cfrac%7B%5Cbar%7Bp%7D%7D%7B%5Calpha%28p%2C%5Cbar%7Bp%7D%29%7D%5Cright%29%5Cright%29+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
This is what it looks like:

Plot of the new upper bound
So clearly causal adversaries are worse than i.i.d. noise (the
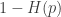 bound).
bound).
To show such a bound we have to propose a new attack for the adversary. We call our attack “babble and push.” It operates in two phases. The first phase is of length 

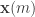

- (Babble) Calvin chooses a random subset
indices uniformly from all
-subsets of
and flips bit
.
- (Push) Calvin finds all possible codewords which are consistent with what Bob has received in the first phase:
,
and selects an element
uniformly at random. For the second phase, Calvin selectively pushes the received codeword towards
— if the transmitted codeword and the selected codeword match, he does nothing, and if they do not match he flips the bit with probability
.
Analyzing this scheme amounts to showing that Calvin can render the channel “symmetric.” This is a common condition in arbitrarily varying channels (AVCs), a topic near and dear to my heart. Basically Bob can’t tell the difference between the real codeword and the transmitted codeword, because under Calvin’s attack, the chance that Alice chose 

It’s relatively clear that this approach would extend to more general AVCs, which we could work on for the future. What is neat to me is that this shows how much value Calvin can derive by knowing the current input bit — by forcing additional uncertainty to Bob during the babble phase, Calvin can buy some time to more efficiently use his bit flipping budget in the second phase.
Memorial page for Tom Cover
Stanford has put up a page where people can leave remembrances of Tom Cover. (h/t Gireeja Ranade)
Tom Cover (1938-2012)
According to Sergio Verdu‘s twitter feed, Tom Cover has passed away. (h/t Alex Dimakis)
CISS 2012 : day 1
I’m at CISS right now on the magnolia-filled Princeton campus. The last time I came here was in 2008, when I was trying to graduate and was horribly ill, so this year was already a marked improvement. CISS bears some similarities to Allerton — there are several invited sessions in which the talks are a little longer than the submitted sessions. However, the session organizers get to schedule the entire morning or afternoon (3 hours) as they see fit, so hopping between sessions is not usually possible. I actually find this more relaxing — I know where I’m going to be for the afternoon, so I just settle down there instead of watching the clock so I don’t miss talk X in the other session.
Because there are these invited slots, I’ve begun to realize that I’ve seen some of the material before in other venues such as ITA. This is actually a good thing — in general, I’ve begun to realized that I have to see things 3 times for me to wrap my brain around them.
In the morning I went to Wojciech Szpankowski‘s session on the Science of Information, a sort of showcase for the new multi-university NSF Center. Peter Shor gave an overview of quantum information theory, ending with comments on the additivity conjecture. William Bialek discussed how improvements in array sensors for multi-neuron recording and other measurement technologies are allowing experimental verification of some theoretical/statistical approaches to neuroscience and communication in biological systems. In particular, he discussed an interesting example of how segmentation appears in the embryonic development of fruit flies and how they can track the propagation of chemical markers during development.
David Tse gave a slightly longer version of his ITA talk (with on DNA sequencing with more of the proof details. It’s a cute version of the genome assembly problem but I am not entirely sure what it tells us about the host of other questions biologists have about this data. I’m trying to wrestle with some short-read sequencing data to understand it (and learning some Bioconductor in the process), and the real data is pretty darn messy.
Madhu Sudan talked about his work with Brendan Juba (and now Oded Goldreich) on Semantic Communication — it’s mostly trying to come up with definitions of what it means to communicate meaning using computer science, and somehow feels like some of these early papers in Information and Control which tried to mathematize linguistics or other fields. This is the magical 3rd time I’ve seen this material, so maybe it’s starting to make sense to me.
Andrea Goldsmith gave a whirlwind tour of the work in backing away from asymptotic studies in information theory, and how insights we get from asymptotic analyses often don’t translate into the finite parameter regime. This is of a piece with her stand a few years ago on cross-layer design. High SNR assumptions in MIMO and relaying imply that certain tradeoffs (such diversity-multiplexing) or certain protocols (such as amplify-and forward) are fundamental but at moderate SNR the optimal strategies are different or unknown. Infinite blocklengths are the bread and butter of information theory but now there are more results on what we can do with finite blocklength. She ended with some comments on infinite processing power and trying to consider transmit and processing power jointly, which caused some debate in the audience.
Alas, I missed Tsachy Weissmann‘s talk, but at least I saw it at ITA? Perhaps I will get to see it two more times in the future!
In the afternoon I went to the large alphabets session which was organized by Aaron Wagner. Unfortunately, Aaron couldn’t make it so I ended up chairing the session. Venkat Chandrasekaran didn’t really talk about large alphabets, but instead about estimating high dimensional covariance matrices when you have symmetry assumptions on the matrix. These are represented by the invariance of the true covariance under actions of a subgroup of the symmetric group — taking these into account can greatly improve sample complexity bounds. Mesrob Ohanessian talked about his canonical estimation framework for large alphabet problems and summarized a lot of other work before (too briefly!) mentioning his own work on the consistency of estimators under some assumptions on the generating distribution.
Prasad Santhanam talked about the insurance problem that he worked on with Venkat Anantharam, and I finally understood it a bit better. Suppose you are observing i.i.d. samples 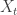


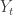

To round out the session, Wojciech Szpankowski gave a talk on analytic approaches to bounding minimax redundancy under different scaling assumptions on the alphabet and sample sizes. There was a fair bit of generatingfunctionology and Lambert W-functions. The end part of the talk was on scaling when you know part of the distribution exactly (perhaps through offline simulation or training) but then there is part which is unknown. The last talk was by Greg Valiant, who talked about his papers with Paul Valiant on estimating properties of distributions on 
I am not sure how much blogging I will do about the rest of the conference, but probably another post or two. Despite the drizzle, the spring is rather beautiful here — la joie du printemps.
ICITS Deadline Extension
Due to conflicts with other deadlines and conferences, the submission
deadline for the “conference” track of ICITS 2012 — the International
Conference on Information-Theoretic Security — has been moved back
ten days to Thursday, March 22, 2012.
The “conference” deadline is now Thursday, March 22 (3pm EDT / 19:00 GMT).
The “workshop” deadline is Monday, April 9.
ICITS will have two tracks this year, one which will act as a regular
computer science-style conference (published proceedings, original
work only) and the other which will behave more like a workshop,
without proceedings, where presentations on previously published work
or work in progress are welcome.
For more information, see the conference website.
