According to the article The Truth About Bender’s Brain in the May 2009 issue of IEEE Spectrum, one of the writers of Futurama, Ken Keeler, “confirms that he does read every issue of IEEE Spectrum and occasionally looks at the Transactions on Information Theory.” So is it true that source coding people are more funny than channel coding people?
Tag Archives: engineering
IEEE : no longer an acronym
I didn’t realize this, but IEEE is not officially an acronym anymore:
The IEEE name was originally an acronym for the Institute of Electrical and Electronics Engineers, Inc. Today, the organization’s scope of interest has expanded into so many related fields, that it is simply referred to by the letters I-E-E-E (pronounced Eye-triple-E).
Was this recent, or has it been like that for a while? Perhaps it’s the family history, but I always thought that IEEE was supposed to be an acronym…
Infocom 2009 : routing
Scalable Routing Via Greedy Embedding
Cedric Westphal (Docomo Labs USA, US); Guanhong Pei (Virginia Tech, US)
In a network, a greedy routing strategy that sends packets to the neighbor closest to the destination may require routing tables of size 
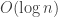



Greedy Routing with Bounded Stretch
Roland Flury (ETH Zurich, Switzerland); Sriram Pemmaraju (The University of Iowa, US); Roger Wattenhofer (ETH Zurich, Switzerland)
This was another talk about greedy routing. If the network has holes in it (imagine a lake) then greedy routing can get stuck because there is no greedy step to take. So there are lots of algorithms out there for recovering when you are stuck. It would be far nicer to get a coordinate system for the graph such that greedy routing always works (in some sense), but so that the stretch is not too bad. This talk proposed a scheme which had three ingredients: spanning trees, separators, and isometric greedy embeddings. Basically the idea (from what I saw in the talk) is to use the existence of separators in the graph to build a tree cover of the graph and then do routing along the best tree in the cover. This guarantees the bounded stretch, and the number of trees needed is not too large, so the labels are not too large either. I think it was a rather nice paper, and between the previous one and this one I was introduced to a new problem I had not thought about before.
Routing Over Multi-hop Wireless Networks with Non-ergodic Mobility
Chris Milling (The University of Texas at Austin, US); Sundar Subramanian (Qualcomm Flarion Technologies, US); Sanjay Shakkottai (The University of Texas at Austin, US); Randall Berry (Northwestern University, US)
In this paper they had a network with some static nodes and some mobile nodes who move in prescribed areas but with no real “model” on their motion. They move arbitrarily according to some arbitrary continuous paths. Some static nodes need to route packets to the mobile nodes. How should they do this? A scheme is proposed in which the static node sends out probe packets to iteratively quarter the network and corral the mobile node. If the mobile crosses a boundary then a node close to the boundary will deliver the packet. An upperbound on the throughput can be shown by considering the mobiles to be at fixed locations (chosen to be the worst possible). This is essentially the worst case, since the rates achieved by their scheme are within a polylog factor of the upper bound. This suggests that the lack of knowledge of the user’s mobility patterns hurts very little in the scaling sense.
The Conyers bill and open access
Allie sent this blog post my way about the Conyers bill, about which Lawrence Lessig has been quite critical. At the moment the NIH requires all publications from research it funds to be posted (e.g. on PubMed) so that the public can read them. This makes sense because the taxpayers paid for this research.
What Conyers wants is to do is end the requirement for free and public dissemination of research. Why? Lessig says he’s in the pocket of the publishing industry. From the standpoint of the taxpayer and a researcher, it’s hard to see a justification for this amendment. Conyers gives a procedural reason for the change, namely that “this so-called ‘open access’ policy was not subject to open hearings, open debate or open amendment.” So essentially he wants to go back to the status quo ante and then have a debate, rather than have a debate about whether we want to go back to the status quo ante.
From my perspective, spending Congressional time to do the equivalent of a Wikipedia reversion is a waste — if we want to debate whether to change the open access rules, let’s debate that now rather than changing the rules twice. I think we should expand open access to include the NSF too. It’s a bit tricky though, since most of my work is published (and publishable) within the IEEE. The professional societies could be a great ally in the open-access movement, but as Phil Davis points out, the rhetoric on both sides tends to leave them out.
Searching for Manet

Infocom 2009 : network statistics problems
Graph Sampling Techniques for Studying Unstructured Overlays
Amir Hassan Rasti Ekbatani (University of Oregon, US); Mojtaba Torkjazi (University of Oregon, US); Reza Rejaie (University of Oregon, US); Nick Duffield (AT&T Labs – Research, US); Walter Willinger (AT&T Labs – Research, US); Daniel Stutzbach (Stutzbach Enterprises LLC, US)
The question in this paper was how to collect network statistics (such as node degree) in peer-to-peer networks. Since peers join and leave, selecting a random peer is difficult because there are biases caused by high-degree peers and low-lifetime peers. One approach to correct for this is to use Markov chain Monte Carlo (MCMC) to sample from the nodes. This talk proposed respondent-driven sampling (RDS), a technique used to map social networks. The idea is to do a random walk on the network and gather statistics along the walk (not just at the end, as in MCMC). These measurements are biased, but then we can correct for the bias at the end (using something called the Hansen-Hurwitz estimator, which I don’t know much about). Experimental works showed a big improvement when vanilla MCMC and RDS were compared on hierarchical scale-free graphs.
A Framework for Efficient Class-based Sampling
Mohit Saxena (Purdue University, US); Ramana Rao Kompella (Purdue University, US)
This talk was about increasing the coverage of monitoring flows in networks. Currently routers sample flows uniformly, which catches the big “elephant” flows but not the low-volume “mouse” flows. In order to increase coverage, the authors propose dividing flows into classes and then sample the classes. So the architecture is to classify a packet first, then choose whether to sample it. The goal is to do a combination of sketching and hashing that shifts the complexity to slower memory, thereby saving costs. They use something called a composite Bloom filter to do this.
Estimating Hop Distance Between Arbitrary Host Pairs
Brian Eriksson (University of Wisconsin – Madison, US); Paul Barford (University of Wisconsin – Madison, US); Rob Nowak (University of Wisconsin, Madison, US)
Given a big network (like the internet) with 

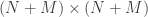
Infocom 2009 : general thoughts and assorted topics
This was my first time going to Infocom, and I had a good time, despite being a bit out of my element. The crowd is a mix of electrical engineers and computer scientists, of theorists, experimentalists, and industry researchers. Although I often would go to a talk thinking I knew what it would be about, I often found that it was rather different than what I expected. At first this was a little alienating, but in the end I found it refreshing to be introduced to a host of new ideas and problems. Unfortunately, the lack of familiarity may translate into some misunderstandings in these posts; as usual, clarifying comments are welcome!
Below are the papers I couldn’t categorize into other areas.
Dynamic Power Allocation Under Arbitrary Varying Channels – An Online Approach
Niv Buchbinder (Technion University, IL); Liane Lewin-Eytan (Technion, IL); Ishai Menache (Massachusetts Institute of Technology, US); Joseph (Seffi) Naor (Technion, IL); Ariel Orda (Technion, IL)
The model is that of an online power allocation problem wherein the gain of a fading channel 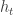




Lightweight Coloring and Desynchronization for Networks
Arik Motskin (Stanford University, US); Tim Roughgarden (Stanford University, US); Primoz Skraba (Stanford University, US); Leonidas Guibas (Stanford University, US)
This paper was on duty-cyling nodes in a sensor network to preserve power and avoid interference. In particular, we would like to color the 



Using Three States for Binary Consensus on Complete Graphs
Etienne Perron (EPFL, Switzerland); Dinkar Vasudevan (EPFL, Switzerland); Milan Vojnovic (Microsoft Research, UK)
This paper looked at a binary consensus problem that was seemed on the face of it quite different from the consensus algorithms that I work on. They consider a complete graph where every node has a an initial value that is either 0 or 1. The goal is to compute the majority vote in all the nodes in a distributed manner while requiring only a small state in each of the nodes. This is related to a standard voter model, in which nodes sample their neighbor and switch their vote if it is different. If we have 3 states, (0, e, 1), where e is “undecided” then we can make a rule where a node samples its neighbor and moves one step in direction reported by the neighbor. Different variants of the algorithm are also analyzed, and the error rate analysis seemed a bit hairy, involving ODEs and so on. What I was wondering at the end is the relationship of this algorithm to standard gossip with one bit quantization of messages.
Greetings from Infocom 2009
Greeting to you, patient (and probably bored) readers! I’m in Rio de Janeiro for Infocom 2009 and yes, I am going to be blogging a bit about it. The conference is little out of my bailiwick, at least so far. I go to sessions and think I might know what the talk is about, based on the title, only to find out I’m completely wrong. It’s good though, and as a challenge to myself I will try to blog about some of the talks a bit (I guess I gave up on finishing my ITA reminiscences).
So keep tuned!
support and discounts for developing countries
I’ve been catching up on my magazine reading and an ad from the AMS Book & Journal Donation Program in the December issue of the Notices of the AMS caught my eye. The program is designed to improve access to mathematical materials in developing countries via donations. The AMS already has discounted membership fees for those in developing countries, and in general the mathematics community seems more sensitive to these kinds of disparities.
I looked around a bit to see if the IEEE had any sort of book donation program, but it doesn’t seem to be an institutionally supported thing. The scalable computing people have a page on donations, but I didn’t see one for the main IEEE page. There are no discounts listed on the subscription price list. It seems like more could and should be done. Just putting more things online isn’t going to fix everything. There is a value in having actual books in a library too.
So what can be done? In terms of textbooks, there are already cheaper editions available from most of the major publishers, so that doesn’t seem to be the bottleneck. Setting up a clearinghouse (as the AMS has done) for more research-oriented titles seems like a relatively simple thing to do. Providing a tiered-pricing scheme for journals would be a next good step. If the impetus for this comes at a high level in the IEEE, it might get chapters (and undergrads!) engaged in helping gather materials, solicit requests for donations, and so on.
Following the Perturbed Leader
I’m reading Cesa-Bianchi and Lugosi’s Prediction, Learning, and Games in more detail now, and in Chapter 4 they discuss randomized prediction and forecasting strategies. The basic idea is that nature has a sequence of states or outcomes 



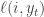
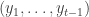
One simple strategy that you might consider is to choose at time

This seems like a good idea at first glance but can easily be “fooled” by a bad state sequence 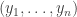
So what to do? One option, proposed by Hannan, is to add noise to all of the empirical losses 

This strategy is Hannan consistent and is called follow the perturbed leader since the action you choose is the best action after a perturbation.
If you got this far, I bet you were thinking I’d make some comment on the election. We’ve been following a perturbed leader for a while now. So here is an exercise : how is this prediction model a bad model for politics?
