My ex-groupmate and fellow Uni High graduate Galen Reeves told me about a paper a few weeks ago when I visited him at Stanford:
Successive Normalization of Rectangular Arrays
Richard A. Olshen and Bala Rajaratnam
The Annals of Statistics 38(3), pp.1369-1664, 2010
Apparently, however, the arguments in the paper are not quite correct [1], and they recently uploaded a correction to ArXiV.
This paper looks at the effect of a very common preprocessing step used to transform an  data matrix
data matrix  into a form acceptable for statistical or machine learning algorithms that assume things like zero-mean or bounded vectors. Here
into a form acceptable for statistical or machine learning algorithms that assume things like zero-mean or bounded vectors. Here  may represent the number of individuals, and
may represent the number of individuals, and  the number of features, for example. Or the data may come from a DNA microarray (their motivating example). This preprocessing is often done without much theoretical justification — the mathematical equivalence of tossing spilled salt over your shoulder. This paper looks at the limiting process of standardizing rows and then columns and then rows and then columns again and again. They further need that
the number of features, for example. Or the data may come from a DNA microarray (their motivating example). This preprocessing is often done without much theoretical justification — the mathematical equivalence of tossing spilled salt over your shoulder. This paper looks at the limiting process of standardizing rows and then columns and then rows and then columns again and again. They further need that 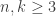 . “Readers will see that the process and perhaps especially the mathematics that underlies it are not as simple as we had hoped they would be.”
. “Readers will see that the process and perhaps especially the mathematics that underlies it are not as simple as we had hoped they would be.”
So what exactly is the preprocessing? I am going to describe things in pseudocode (too lazy to do real code, sorry). Given a data matrix X[i,j] they look at
for i = 1:n { X[i,1:k] = X[i,1:k] - sum(X[i,1:k]) }
for j = 1:k { X[1:n,j] = X[l:n,j] - sum(X[1:n,j]) }
They call the first a “row mean polish” and the second a “column mean polish.” They show this converges in one step.
But what about standardizing? The more complicated polishing procedure looks like this:
for i = 1:n {
mu = sum(X[i,1:k])
sigma = sqrt( sum( (X[i,1:k] - mu)^2 ) )
X[i,1:k] = (X[i,1:k] - mu)/sigma
}
for j = 1:k {
mu = sum(X[1:n,j])
sigma = sqrt( sum( (X[1:n,j] - mu)^2 ) )
X[1:n,j] = (X[1:n,j] - mu)/sigma
}
This standardizes rows first, and then columns (or “lather” and “rinse,” since we are going to “repeat”). They call this Efron‘s algorithm because he told them about it. So what happens if we repeat these two steps over and over again on a matrix with i.i.d. entries from some continuous distribution?
Theorem 4.1 Efron’s algorithm converges almost surely for X on a Borel set of entries with complement a set of Lebesgue measure 0.
So what does it look like in practice? How fast is this convergence? Empirically, it looks exponential, and they have some theoretical guarantees in the paper, kind of hidden in the discussion. The proofs are not terribly ornate but are tricky, and I don’t quite get all the details myself, but I figured readers of this blog would certainly be interested in this cute result.
[1] A fun quote from the paper “Theorem 4.1 of [2] is false. A claimed backwards martingale is NOT. Fortunately, all that seems damaged by the mistake is pride. Much is true.” I really liked this.
 of coming up heads. You can flip the coin as many times as you like (or more precisely, you can flip the coin an infinite number of times). Let
of coming up heads. You can flip the coin as many times as you like (or more precisely, you can flip the coin an infinite number of times). Let 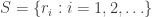 be the set of rational numbers in
be the set of rational numbers in ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . After each flip, you have to guess one of the following hypotheses: that
. After each flip, you have to guess one of the following hypotheses: that  for a particular
for a particular  , or
, or ![p \in [0,1] - N_0](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C1%5D+-+N_0&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where 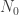 is a set of irrationals of Lebesgue measure 0. Can you do it? If so, how?
is a set of irrationals of Lebesgue measure 0. Can you do it? If so, how? you have a function
you have a function 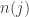 . Think of
. Think of 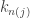 , and an interval width
, and an interval width  .
. 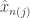 and look at a interval of width
and look at a interval of width 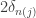 centered on it. Note that this makes the same decision for each
centered on it. Note that this makes the same decision for each  until
until  , find the smallest
, find the smallest ![r_i \in [\hat{x} - \delta_{n(j)}, \hat{x} + \delta_{n(j)}]](https://s0.wp.com/latex.php?latex=r_i+%5Cin+%5B%5Chat%7Bx%7D+-+%5Cdelta_%7Bn%28j%29%7D%2C+%5Chat%7Bx%7D+%2B+%5Cdelta_%7Bn%28j%29%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.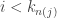 such that
such that 
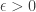 ,
,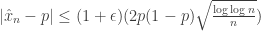
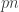 total bit flips. That is, Calvin is causal : the decision to flip bit
total bit flips. That is, Calvin is causal : the decision to flip bit 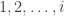 . What we show is a new upper bound on the capacity of this channel. Let
. What we show is a new upper bound on the capacity of this channel. Let 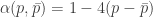 . Then
. Then![C \le \min_{\bar{p} \in [0,p]} \left[ \alpha(p,\bar{p})\left(1-H\left(\frac{\bar{p}}{\alpha(p,\bar{p})}\right)\right) \right]](https://s0.wp.com/latex.php?latex=C+%5Cle+%5Cmin_%7B%5Cbar%7Bp%7D+%5Cin+%5B0%2Cp%5D%7D+%5Cleft%5B+%5Calpha%28p%2C%5Cbar%7Bp%7D%29%5Cleft%281-H%5Cleft%28%5Cfrac%7B%5Cbar%7Bp%7D%7D%7B%5Calpha%28p%2C%5Cbar%7Bp%7D%29%7D%5Cright%29%5Cright%29+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)

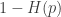 bound).
bound).
 channel uses and the second of length
channel uses and the second of length  . Let
. Let 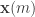 be the codeword for message
be the codeword for message  .
. indices uniformly from all
indices uniformly from all 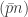 -subsets of
-subsets of 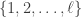 and flips bit
and flips bit 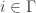 .
.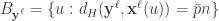 ,
, uniformly at random. For the second phase, Calvin selectively pushes the received codeword towards
uniformly at random. For the second phase, Calvin selectively pushes the received codeword towards  — if the transmitted codeword and the selected codeword match, he does nothing, and if they do not match he flips the bit with probability
— if the transmitted codeword and the selected codeword match, he does nothing, and if they do not match he flips the bit with probability  .
. and Calvin chose
and Calvin chose  is the same as the chance Alice chose
is the same as the chance Alice chose  . To establish this symmetry condition requires some technical excursions which are less fun to blog about, but were fun to figure out.
. To establish this symmetry condition requires some technical excursions which are less fun to blog about, but were fun to figure out.