In giving talks to broader audiences about differential privacy, I’ve learned quickly (thanks to watching talks by other experts) that discussing randomized response first is an easy way to explain the kind of “plausible deniability” guarantee that differentially private algorithms give to individuals. In randomized response, the setup is that of local privacy: the simplest model is that a population of 

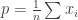
The surveyor can give the individuals a biased coin that comes up heads with probability 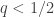



![\mathbb{E}\left[ \frac{1}{n} \sum_{i=1}^{n} y_i \right] = \frac{1}{n} \sum_{i=1}^{n} (q (1 - x_i) + (1 -q) x_i) = q + (1 - 2q) p](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+y_i+%5Cright%5D+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%28q+%281+-+x_i%29+%2B+%281+-q%29+x_i%29+%3D+q+%2B+%281+-+2q%29+p&bg=ffffff&fg=333333&s=0&c=20201002)
So we can invert this to solve for 


What does this have to do with differential privacy? Each individual got to potentially lie about their drug habits. So if we look at the hypothesis test for a surveyor trying to figure out if someone is a user from their response, we get the likelihood ratio

If we set 



Epsilon versus lying probability
This is a bit pessimistic — it says that to guarantee reasonable “lying probability” we need 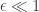
So how does randomized response work in practice? It seems we would need a biased coin. Maybe one can custom order them from Alibaba? Turns out, the answer is not really. Gelman and Nolan have an article about getting students to try and evaluate the bias of a coin — the physics of flipping would seem to dictate that coins are basically fair. You can load dice, but not coins. I recommend reading through the article — it sounds like a fun activity, even for graduate students. Maybe I’ll try it in my Detection and Estimation course next semester.
Despite the widespread prevalence of “flipping a biased coin” as a construction in probability, randomized algorithms, and information theory, a surprisingly large number of people I have met are completely unaware of the unicorn-like nature of biased coins in the real world. I guess we really are in an ivory tower, eh?

I am surprised to learn this about coins. I’d assumed that there were novelty manufacturers at least who made biased or bias-able coins.
Yeah me too! I had it on my list to order a box in case I got a chance to do a demo or something, but it turns out there’s no such thing. I felt sad and then also embarrassed for not knowing this.
Pingback: Where Are The Unfair Coins? | nebusresearch