I took a look at this interesting paper by Sriperumbudur et al., On the empirical estimation of integral probability metrics (Electronic Journal of Statistics Vol. 6 (2012) pp.1550–1599). The goal of the paper is to estimate a distance or divergence between two distributions 

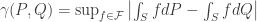
where 


Different choices of the function class give rise to different measures of difference used in so-called two-sample tests, such as the Kolmogorov-Smirnov test. The challenge in practically using these tests is that it’s hard to get bounds on how fast an estimator of 
The second section of the paper connects tests based on IPMs with the risk associated to classification rules for separating
Getting back to KL divergence and non-IPM measures, since total variation gives a lower bound on the KL divergence, they also provide lower bounds on the total variation distance in terms of other IPM metrics. This is important since the total variation distance can’t be estimated itself in a strongly consistent way. This could be useful for algorithms which need to estimate the total variation distance for continuous data. In general, estimating distances between multivariate continuous distributions can become a bit of a mess when you have to use real data — doing a plug-in estimate using, e.g. a kernel density estimator is not always the best way to go, and instead attacking the distance you want to measure directly could yield better results.
