Dhruv Batra forwarded this Communications of the ACM article by Pedro Domingos, entitled “A Few Useful Things to Know about Machine Learning” [free version] The main point from the abstract is:
However, developing successful machine learning applications requires a substantial amount of “black art” that is hard to find in textbooks. This article summarizes twelve key lessons that machine learning researchers and practitioners have learned. These include pitfalls to avoid, important issues to focus on, and answers to common questions.
The article focuses on the classification problem to illustrate these “key lessons.” It’s well-worth reading, especially for people who don’t work on machine learning because it explains a number of important issues.
- It illustrates the gap between what the theory/research works on and the nitty-gritty of applying these algorithms to real data.
- It gives people who want to implement an ML method important fundamental questions to ask before starting : how do I represent my data? How do I evaluate performance? How do I do things efficiently? These have to get squared away first.
- Domain knowledge and feature engineering are the keys to success.
Since I’m guessing there are 2 machine learners who read this blog, go read it (unless you are one of my friends who doesn’t care about all of these technical posts).

 and
and 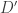 , we want to analyze the behavior of the random variable
, we want to analyze the behavior of the random variable  for measurable sets
for measurable sets  .
. 