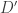On Saturday I attended the 2nd iDASH workshop on privacy — I thought overall it went quite well, and it’s certainly true that over the last year the dialogue and understanding has improved between the theory/algorithms, data management/governance, and medical research communities. I developed note fatigue partway through the day, but I wanted to blog a little bit about some of the themes which came up during the workshop. Instead of making a monster post which covers everything, I will touch on a few things here. In particular, there were other talks not mentioned below about issues in data governance, cryptographic approaches, special issues in genomics, study design, and policy. I may touch on those in later posts.
Cynthia Dwork and Latanya Sweeney gave the keynotes, as they did last year, and they dovetailed quite nicely this year. Cynthia’s talk centered on how to think of privacy risk in terms of resource allocation — you have a certain amount of privacy and you have to apportion it over multiple queries. Latanya Sweeney’s talk came from the other direction: the current legal framework in the US is designed to make information flow, and so it is already a privacy-unfriendly policy regime. These raise some serious impediments to practically implementing privacy protections that we develop on the technological side.
On the privacy models side, Ashwin Machanavajjhala, Chris Clifton talked about slightly different models of privacy that are based on differential privacy but have a less immediately statistical feel, based on work from PODS 2012 and KDD 2012. Kamalika Chaudhuri talked about our work on differentially private PCA, and Li Xiong talked about differential privacy on time series using adaptive sampling and prediction.
Guy Rothblum talked about something he called “concentrated differential privacy,” which essentially amounts to analyzing the measure concentration properties of the log-likelihood ratio that appears in the differential privacy definition : for any two databases