The Allerton 2012 early registration deadline is this Friday. I tried registering at the link they sent but found I had to click on the “submit a paper” button on the main PaperCept page, so YMMV.
Monthly Archives: September 2012
Linkage
I’m a big fan of 99% Invisible, a podcast about design and architecture and… stuff. They rebroadcast a longer piece about U.N. Plaza in San Francisco, and it’s fascinating. I was living in Berkeley at the time much of this went down, and I was semi-unaware of it.
A post from the new desi blog, Brown Town, about Freddie Mercury.
My cousin Supriya has e-books in Hindi, Marathi, and Gujarati available. You know, for kids!
My very dear (but not so near) friend Charlotte has a new blog : Mary Magdalene Girl in which she will discuss gender and her un-diasporaing (not a word) by moving to Ireland.
Photos of yakuza. Unrelatedly, construction worker fashion in Japan.
Approaches to the research statement
It’s job season again and I am revising my research statement. I was pretty happy with the last iteration of it, but as things change I might need to find a new story for my life. As I get farther along, it has become a bit harder to cram all of the things I’ve worked on into a single consistent story. There are even some grad students I know who have worked on several distinct things and they probably have the same problem. There’s a tension in the research statement between coming up with a coherent story and accurately representing your work. There are a few generic ways of handling this, it seems.
The omnibus. You can write many mini-stories, one about each of the major projects, and then have a section for “miscellaneous other papers.” This approach eschews the overarching framework idea and instead just goes for local internal consistency.
The proposal. Instead of talking about all of your work (or mentioning it), you propose one research direction and give short shrift to the rest. This has the advantage of letting you write more fully about one topic and provide sufficient context and exciting new research directions, but then again you’re mis-representing the actual balance of your research interests.
The tractatus. You develop some principles or philosophical underpinnings for your work and then try to connect everything you’ve done to these and explain your future work ideas as further developing these themes. This approach goes for consistency above all else. The advantage is coherence, and the disadvantage is that some projects may have to get strong-armed into it.
I am sure there are more varieties out there, but on the whole the research statement is a weird document — part description, part proposal. You can’t make it only about your existing work because that’s looking to the past, but you can’t make it a proposal because the reader is actually trying to learn what you are interested in.
Broadcast gossip revisited : companion variables and convergence to consensus
Mike Rabbat pointed out his new preprint on ArXiv:
Broadcast Gossip Algorithms for Consensus on Strongly Connected Digraphs
Wu Shaochuan, Michael G. Rabbat
The basic starting point is the unidirectional Broadcast Gossip algorithm — we have 


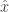

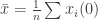
![\mathbb{E}[\hat{x}] = \bar{x}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Chat%7Bx%7D%5D+%3D+%5Cbar%7Bx%7D&bg=ffffff&fg=333333&s=0&c=20201002)
The reason broadcast gossip does’t compute the average is pretty clear — since the communication and updates are unidirectional, the average of the nodes’ values changes over time. One way around this is to use companion variables 
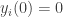





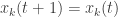

So what’s going on here? Each time a node transmits it resets its companion variable to 
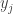
The parameters of the algorithm are matrices 




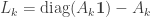

When node
![W_k \left[ \begin{array}{cc} I - L_k & \epsilon D_k \\ L_k & S_k - \epsilon D_k \end{array} \right]](https://s0.wp.com/latex.php?latex=W_k+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+I+-+L_k+%26+%5Cepsilon+D_k+%5C%5C+L_k+%26+S_k+-+%5Cepsilon+D_k+%5Cend%7Barray%7D+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
such that
![\left[ \begin{array}{c} \mathbf{x}(t+1) \\ \mathbf{y}(t+1) \end{array} \right]^T = W(t) \left[ \begin{array}{c} \mathbf{x}(t) \\ \mathbf{y}(t) \end{array} \right]^T](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%2B1%29+%5C%5C+%5Cmathbf%7By%7D%28t%2B1%29+%5Cend%7Barray%7D+%5Cright%5D%5ET+%3D+W%28t%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+%5Cmathbf%7Bx%7D%28t%29+%5C%5C+%5Cmathbf%7By%7D%28t%29+%5Cend%7Barray%7D+%5Cright%5D%5ET&bg=ffffff&fg=333333&s=0&c=20201002)
where 
The main results are:
- If we choose
small enough, then
and
under more conditions.
- A sufficient condition for the second moment of the error to go to 0.
- Rules on how to pick the parameters, especially
There are also some nice simulations. Broadcast gossip is nice because of its simplicity, and adding a little monitoring/control variable 
The editor-in-chief has a new stick
Here’s a little bit of news which may have escaped notice by some in the information theory community:
“In view of its concerns about excessive reviewing delays in the IT Transactions, the BoG authorizes the EiC in his sole judgment to delay publication of papers by authors who are derelict in their reviewing duties.”
Reviewers may be considered to be derelict if they habitually decline or fail to respond to review requests, or accept but then drop out; or if they habitually submit perfunctory and/or excessively delayed reviews.
I’ve said it before, but I think that transparency is the thing which will make reviews more timely — what is the distribution of review times? What is the relationship between paper length and review length? Plots like these may shock people and also give a perspective on their own behavior. I bet some people who are “part of the problem” don’t even realize that they are part of the problem.
The card-cyclic to random shuffle
I heard about this cool-sounding seminar at the Berkeley Statistics department:
Mixing time of the card-cyclic to random shuffle
Ben MorrisWe analyze the following method for shuffling
rounds.
The talk is based on a paper with Weiyang Ning (a student at UW) and Yuval Peres. The description the results is somewhat different because it’s 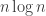
To prove the lower bound we introduce the concept of a barrier between two parts of the deck that moves along with the cards as the shuffling is performed. Then we show that the trajectory of this barrier can be well-approximated by a deterministic function
… we relate the mixing rate of the chain to the rate at which
The key is to use path coupling, a technique pioneered by Bubley and Dyer. It’s a cute result and would be a fun paper to read for a class project or something, I bet.
Five career-oriented things I wish I had done more of in grad school
As I’ve started my nascent academic career, I’ve faced a number of new and difficult challenges, and on more than one occasion I’ve felt hoisted with my own petard. Looking back on my graduate school experience, I realized there were a number of things which I could have done more that would have made things easier now.
- Write more grants. I came in to grad school with a NDSEG fellowship and then my advisor was well-funded. I had a blesséd life (especially compared to those in other departments). I should have gotten a bit more on the ball helping to write grants, even if it was just for the experience. Reading a proposal (or many) really gives a sense of what the document is about. More importantly, it’s a grant in your field and that’s something that you can’t really get out of one of those panels on grantsmanship that are pitched to a broad audience. Learning the process early has two benefits : it demystifies the strategy space in terms of writing, and it gives a good sense of what kind of things make sense and are “fundable.” I wrote little dribs and drabs of proposals here and there but it wasn’t until my postdoc that I really got to see and work on a full proposal.
- Do an internship. : It’s sad to say, but I never did an internship while in grad school. This was a real mistake. As an engineer it’s important to learn what is going on in “real” engineering but more importantly, as a engineering theorist it’s important to understand what’s going to be important in the future. Some of that you can do by watching the news and trends, but having a visceral sense of the challenges in making a real object is an important perspective. On the more practical side, it gives you more contacts in industry and the more people you know, the more ideas you can integrate.
- Constantly tell stories. : Part of this is for grant writing, but it’s a more general skill that is important for the job market and interacting with your colleagues, 99% of whom will be outside your area. This is a skill that is hard to develop in graduate school because we spend our time in our labs talking to other graduate students who are not that far away from us in terms of intellectual background. This kind of story-telling is often cast as “be able to talk to the general public” or “explain your research to a crowd that includes information theorists and device physicists.” Part of being able to tell a story about your research is being able to tell it in someone else’s language, which means understanding a bit about how people in other fields think. How would you explain your research to an anthropologist? I did practice explaining to other people, but I wish I had practiced more.
- Find a community. : I do a lot of work that falls between fields or on the corners of fields, so I’ve bounced around a bit. The last time I applied for jobs I had interviews wearing a networks hat, a signal processing hat, and an information theorist hat. Finding a community can have a positive or negative connotation. On the one hand, it’s dumb that people care so much about labels : “oh, he’s a machine learning guy,” or “oh, he’s a signal processing guy.” On the other hand, cultivating professional relationships with a research community is valuable because those are the people who will remember you when your name comes up.
- Write the journal version first. People always say this. I think Lalitha told me this in 2005 at my first conference. Of course it’s a good idea. And it’s a slippery slope if you let it slide for one paper… 5 years later you realize you have 4 nascent journal papers with nice full stories but not enough time to do the last bit of research or flesh out the results a bit more. Not every conference paper is (or should be) a journal-worthy idea. But the goal is to tell bigger stories than 4 page ICASSP paper, and it’s important to keep that bigger picture in mind. I wish I had done more work contextualizing some of the things I worked on so I could come back to them and expand on them later. Instead I have a lot of weird half-baked ideas in old PDFs sitting around on my hard drive.
