I came down with the flu at the tail end of ITA, so I proceeded to fail at a bunch of things, like submitting reviews that were due, writing a submission for ISIT, and blogging the ITA Workshop in time. Cosma already blogged about his favorite talks, beating me to the punch.
I basically missed the first day because of technical glitches with our registration system, but once that was all resolved things went a bit more smoothly (at least I hope they did). The poster session seemed well-attended, and we shot videos of all the posters which will be posted at some point. Ofer did a great job arranging the Graduation Day and poster events. The thing about these conferences is that you end up wanting to talk to people you haven’t seen in a while, and it’s good to hammer out research ideas during the daytime, so I only made it to the keynote and Xiao-Li Meng’s tutorial on MCMC. I felt like I followed the tutorial at the beginning, but even Prof. Meng’s engaging speaking style lost me when it came to modeling something about stars (?). But there will be videos posted of the tutorials soon enough as well. I’ll probably make a post about those. For those who were at the entertainment program, of course the video for that was top priority. For the small number of those blog readers who wish to know what I was making:
- 2 oz. Maker’s Mark bourbon
- 1 oz. Carpano Antica formula vermouth
- 1 dash Angostura bitters
- 1 dash Regan’s No. 6 orange bitters
Shaken with ice, served up with a cherry. I opted for a bourbon Manhattan with a cherry rather than a rye Manhattan with an orange twist (or without garnish) because it was more convenient, and also more 1960s versus craft cocktail.
But on to the talks! I did manage to drag my lazy butt to some of them.
Improved rate-equivocation regions for secure cooperative communication
Ninoslav Marina, Hideki Yagi, H. Vincent Poor
They looked at a model where you have a transmitter and also a “blind” helper who is trying to help communicate over a wiretap channel. They show a better achievable rate-equivocation region by introducing another auxiliary random variable (big surprise!), but this doesn’t affect the best secrecy rate. So if you are willing to tolerate less than full equivocation at the eavesdropper then you’ll get an improvement.
Shannon’s inequality
S. Verdú, Princeton
Sergio talked about an alternative to Fano’s inequality used by Shannon:
It was a nice talk, and the kind of talk I think is great at ITA. It’s not a new result, but ITA is a place where you can give a talk that explains some cool connection or new idea you have.
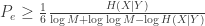
On the zero-error capacity threshold for deletion channels
Ian A. Kash, Michael Mitzenmacher, Justin Thaler, Jon Ullman
A nice piece of work on connecting zero-error capacity for deletion channels with longest common subsequences. The error model is adversarial. You can make a graph where each vertex is a length-
Data-driven decision making in healthcare systems
Mohsen Bayati, Stanford, Mark Braverman, U Toronto, Michael Gillam, Microsoft, Mark Smith, Medstart Health, and Eric Horvitz, Microsoft Research
This was a nice talk on doing feature selection via ideas from sparse signal processing/machine learning. The idea is to find a small set of features to help predict whether a patient is high-risk or low-risk for being readmitted soon after being discharged from the hospital. The idea is that the number of features is huge but the number of data points is small. They do an L1 penalized logistic regression and then derive a threshold based on the cost of doing an intervention (e.g. house-visits for high-risk patients).
Tracking climate models: advances in Climate Informatics
Claire Monteleoni, Columbia CCLS, Gavin A. Schmidt, NASA and Columbia, Shailesh Saroha, and Eva Asplund, Columbia Computer Science
This was an overview of Claire’s work on climate informatics. The basic problem was this : given several models (large-scale simulated systems based on PDEs etc. derived from physics) that predict future temperature, how should you combine them to produce more accurate predictions. She used some tools from her previous works on HMMs to get a system with better prediction accuracy.
On a question of Blackwell concerning hidden Markov chains
Ramon van Handel
The problem is trying to estimate the entropy rate of a process that is a function of a Markov chain (and hence not a Markov chain itself). “Does the conditional distribution of an ergodic hidden Markov chain possess a unique invariant measure?” This was a great talk for the Blackwell session because it started from a question posed by Blackwell and then revisited a few of his other works. Pretty amazing. Oh, and the paper (or one of them).
I think more talks will have to wait for another time (if ever).
