These were a few more “traditional information theory” talks that I had reasonable notes on. The remainder of my ITA posts will be on topics further afield.
Distributed functional scalar quantization with limited encoder interaction
Vinith Misra, Stanford, Vivek K Goyal, MIT, and Lav R. Varshney, MIT
I had looked at an earlier results on this problem and now I think I get it a little better. The regime they look at is high-rate quantization, in which the quantization points are represented by a normalized point density and the distortion is calculated with respect to that. They want to compute some function  of
of  different source variables encoded separately. So we can choose a point density function
different source variables encoded separately. So we can choose a point density function  for each of the variables, write the MSE of estimating
for each of the variables, write the MSE of estimating  in terms of those and then optimize. It turns out that a key parameter is the “functional sensitivity” of at each coordinate, which is given by the expectation of the i-th derivative conditioned on the value of
in terms of those and then optimize. It turns out that a key parameter is the “functional sensitivity” of at each coordinate, which is given by the expectation of the i-th derivative conditioned on the value of  . This decouples the design of the quantizers and leads to a performance improvement. As an extension they look at cases where the encoders can “chat” in the sense that they can somehow choose the function to be computed… and that part I didn’t understand so well.
. This decouples the design of the quantizers and leads to a performance improvement. As an extension they look at cases where the encoders can “chat” in the sense that they can somehow choose the function to be computed… and that part I didn’t understand so well.
Bounds for interactive computation in collocated networks
Nan Ma, Boston University, Prakash Ishwar, Boston University, and Piyush Gupta, Bell Labs
The model here is that every sensor observes one component of a joint source 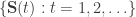 . The decoder wants to estimate
. The decoder wants to estimate  , and the sensors can broadcast messages to all other sensors. They get a rate region related to iterated conditioning on all past messages and then make a connection to communication complexity and monochromatic rectangles (c.f. the book by Kushilevitz and Nisan). As an example, they show that to compute the parity function of binary sources, the destination basically has to recover all the sources.
, and the sensors can broadcast messages to all other sensors. They get a rate region related to iterated conditioning on all past messages and then make a connection to communication complexity and monochromatic rectangles (c.f. the book by Kushilevitz and Nisan). As an example, they show that to compute the parity function of binary sources, the destination basically has to recover all the sources.
Erasure descriptions
Ebad Ahmed and Aaron B. Wagner, Cornell University
This talk discussed a multiple descriptions problem with a binary source and the erasure distortion measure (erasures cost 1, errors cost infinity). The encoder provides rate  descriptions, any
descriptions, any  of which should allow recovery of the whole source. Furthermore, there should be no excess rate, meaning the
of which should allow recovery of the whole source. Furthermore, there should be no excess rate, meaning the  since the decoder with descriptions needs at most total rate 1 to recover the source. The question is what happens to the distortion for decoders who get fewer descriptions. They have some hand-tweaked code constructions for certain cases but not a general construction (yet). Furthermore, via random coding arguments they can make some Pareto optimality claims.
since the decoder with descriptions needs at most total rate 1 to recover the source. The question is what happens to the distortion for decoders who get fewer descriptions. They have some hand-tweaked code constructions for certain cases but not a general construction (yet). Furthermore, via random coding arguments they can make some Pareto optimality claims.
Variable-rate channel capacity
Sergio Verdu, Princeton University, and Shlomo Shamai, Technion
For source coding we have {variable,fixed}-to-{variable,fixed} coding schemes, which gives 4 alternatives to look at, but in channel coding, what do we have? This talk looked at some formulations for problems and how one might define capacity. In variable-to-fixed, we can think of the encoder having an infinite reservoir of bits which has to get mapped to a codeword in  . We count the number
. We count the number 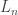 of consecutively recovered bits and define the rate as
of consecutively recovered bits and define the rate as ![\lim \inf_{n \to \infty}\mathbb{E}[L_n]/n](https://s0.wp.com/latex.php?latex=%5Clim+%5Cinf_%7Bn+%5Cto+%5Cinfty%7D%5Cmathbb%7BE%7D%5BL_n%5D%2Fn&bg=ffffff&fg=333333&s=0&c=20201002) . We can think of fixed-to-variable codes as rateless codes, where we try to send bits over a variable blocklength
. We can think of fixed-to-variable codes as rateless codes, where we try to send bits over a variable blocklength 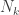 and define the rate as
and define the rate as ![\lim \inf_{n \to \infty} \mathbb{E}[k/N_k]](https://s0.wp.com/latex.php?latex=%5Clim+%5Cinf_%7Bn+%5Cto+%5Cinfty%7D+%5Cmathbb%7BE%7D%5Bk%2FN_k%5D&bg=ffffff&fg=333333&s=0&c=20201002) . Some results were shown on the relationship of these capacities to each other. When the channel has a strong converse then they are all equal and equal to the Shannon capacity. Some relationship to broadcast channels was discussed.
. Some results were shown on the relationship of these capacities to each other. When the channel has a strong converse then they are all equal and equal to the Shannon capacity. Some relationship to broadcast channels was discussed.

Maybe I can clarify about the first of these talks? “Chatting” is an extension of distributed source coding wherein the encoders may communicate (“chat”) amongst one another before communicating to the decoder. In essence, it bridges the gap between jointly encoding the source vector (unlimited chatting) and separately encoding the vector’s components (no chatting).
The two main results pertaining to chatting were:
(1) for fixed-rate, one bit of chatting information does at best as well as one bit sent to the decoder.
(2) for variable-rate, no such bound exists. Chatting can be arbitrarily helpful.
The source of the confusion may be in the geometrical arguments used to obtain these results. Treating functional sensitivities as vectors, the effect of N-bit chatting is to break these vectors into a sum of 2^N vectors. Choosing information to chat is equivalent to choosing how to best “break up” the functional sensitivities.
I hope this helps more than it hinders!
-Vinith
Ah thanks! So it’s a bit like conferencing encoders for the MAC.
I think my confusion stemmed from poor notes plus time lapse before blogging about it. I wonder if your “breaking up” arguments can be reconciled with the “monochromatic rectangle” viewpoint from communication complexity (as Prakash talked about).
Your analogy is right on; I actually have a slight preference for the term “conferencing.”
The communication complexity viewpoint is (as I understand it) concerned with discrete-valued variables and functions, and the quantization viewpoint has difficulty dealing with functions that aren’t smooth/differentiable/etc. It’s tempting to label the two as oil and water.
However, similarities do emerge when one studies non-regular quantization (quantizer “intervals” can be the union of disjoint intervals). We actually use something similar to lemma 1 from arXiv:0901.2356 to demonstrate that non-regular quantization is usually suboptimal.
Thanks for sparing the brain cycles!
-Vinith
(side note: I’m rarely a fan of gratuitous name-dropping, but the coincidence is a little too strange to pass up. About a year ago, Michael Ouellette and several other dramashop-affiliates mentioned an “Anand” at berkeley, as did Lav. I’ve encountered the blog before, but it’s taken me a while to put the pieces together… you are the individual in question, no?)
Guilty as charged! Ah, Dramashop! Those were the good old days, when I could survive on a large coffee and a Clif bar.