I’m not going to organize these posts by topic, mostly because I don’t think it makes a big difference. This is a small selection of the talks which I attended at the Information Theory and Application Workshop that happened last week here at UCSD.
Guaranteed error correction capability of codes on graphs
Shashi Kiran Chilappagari, Bane Vasic and Michael Marcellin
LDPC codes are not my forte, but the idea here seemed to be that the bounds on error correction capabilities from random graphs are often pretty pessimistic (for example, expanders could correct some fraction of a percent of errors — this has since been improved, I understand). It would be nice to express the error correction capability in terms of graph properties. For example, how many errors can can column weight 3 codes correct? In graphs with large girth, decoding fails because of cycles, but there are also bad non-cyclic structures like trapping sets. They mentioned a method for detecting these structures using a 2-bit message-passing algorithm (rather than one bit), which improves the error correction capability. I believe there was also something about how Gallager A cannot correct a linear fraction of errors, but I may have misunderstood that point.
Approximating matches made in heaven
N. Chen, N. Immorlica, A. Karlin, M. Mahdian,and A. Rudra
This was about a matching problem motivated by situations in which vertices are “impatient” to get matched and so will exit the system after a certain time. This may happen in online dating or in kidney transplants (these were the two examples given). Each vertex gets an integer patience parameter and the edges between vertices have weights 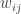

Statistical interference management: An information theoretic view
Nilesh Khude, Vinod Prabhakaran,and Pramod Viswanath
This talk was on the compound interference channel. The idea is that you don’t know if there is interference there or not, but you want to take advantage of any extra capacity you can get. Naturally, the idea is to nest the messages — if the situation is bad, then the receivers decode less, and if not, they decode more. They characterize the capacity region to within a constant gap. What was interesting is that there are three regimes. If the interference gain is low, then one can gain a lot by using a superposition scheme. As the interference gain increases, the benefits tapers off (and the corresponding scheme becomes a complicated Han-Kobayashi code with clever power splitting), and eventually the optimal strategy is to assume the interference is always there.
An information-theoretic view of the Witsenhausen counterexample
Anant Sahai, Pulkit Grover, and Se Yong Park
This talk was fascinating, but I don’t think I could do it justice in a paragraph. The Witsenhausen counterexample is a simple example of a distributed control problem where everything is linear, Gaussian, and quadratic, but for which the best linear strategy can be arbitrarily bad. It turns out that the problem is very related to dirty paper coding and they can find a better converse than Witsenhausen’s that suggests a scheme which is within a factor of 2 of the optimal cost (a 2-approximation, I guess). There is a nice handout which has some more information on it.
Some results on the capacity of channels with insertions, deletions and substitutions
Dario Fertonani and Tolga M. Duman, Arizona State
The channel model is that 


