I’m reading Cesa-Bianchi and Lugosi’s Prediction, Learning, and Games in more detail now, and in Chapter 4 they discuss randomized prediction and forecasting strategies. The basic idea is that nature has a sequence of states or outcomes 



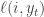
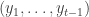
One simple strategy that you might consider is to choose at time

This seems like a good idea at first glance but can easily be “fooled” by a bad state sequence 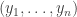
So what to do? One option, proposed by Hannan, is to add noise to all of the empirical losses 

This strategy is Hannan consistent and is called follow the perturbed leader since the action you choose is the best action after a perturbation.
If you got this far, I bet you were thinking I’d make some comment on the election. We’ve been following a perturbed leader for a while now. So here is an exercise : how is this prediction model a bad model for politics?
