Via Andrew Gelman comes a link to deplump, a new compression tool. It runs the data through a predictive model (like most lossless compressors), but:
Deplump compression technology is built on a probabilistic discrete sequence predictor called the sequence memoizer. The sequence memoizer has been demonstrated to be a very good predictor for discrete sequences. The advantage deplump demonstrates in comparison to other general purpose lossless compressors is largely attributable to the better guesses made by the sequence memoizer.
The paper on the sequence memoizer (by Wood et al.) appeared at ICML 2009, with follow-ups at DCC and ICML 2010 It uses as its probabilistic model a version of the Pitman-Yor process, which is a generalization of the “Chinese restaurant”/”stick-breaking” process. Philosophically, the idea seems to be this : since we don’t know the order of the Markov process which best models the data, we will let the model order be “infinite” using the Pitman-Yor process and just infer the right parameters, hopefully avoiding overfitting while being efficient. The key challenge is that since the process can have infinite memory, the encoding seems to get hairy, which is why “memoization” becomes important. It seems that the particular parameterization of the PY process is important to reduce the number of parameters, but I didn’t have time to look at the paper in that much detail. Besides, I’m not as much of a source coding guy!
I tried it out on Leo Breiman’s paper Statistical Modeling: The Two Cultures. Measured in bytes:
307458 Breiman01StatModel.pdf original
271279 Breiman01StatModel.pdf.bz2 bZip (Burrows-Wheeler transform)
269646 Breiman01StatModel.pdf.gz gzip
269943 Breiman01StatModel.pdf.zip zip
266310 Breiman01StatModel.pdf.dpl deplump
As promised, it is better than the alternatives, (but not by much for this example).
What is interesting is that they don’t seem to cite much from the information theory literature. I’m not sure if this is a case of two communities working on related problems and unaware of the connections or that the problems are secretly not related, or that information theorists mostly “gave up” on this problem (I doubt this, but like I said, I’m not a source coding guy…)
 with parameters
with parameters  . Here’s a little follow-up with plots. This is a plot of
. Here’s a little follow-up with plots. This is a plot of  versus
versus  for different values of
for different values of  .
. . Looks beautifully scalloped, no? As we’d expect, the MAD is symmetric about
. Looks beautifully scalloped, no? As we’d expect, the MAD is symmetric about 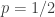 and monotonically increasing for the first half of the unit interval. Unfortunately, it’s clearly not concave (although it is piecewise concave), which means I have to do a bit more algebra later on.
and monotonically increasing for the first half of the unit interval. Unfortunately, it’s clearly not concave (although it is piecewise concave), which means I have to do a bit more algebra later on.


 . So
. So  is the expected total variational distance between the empirical distribution and its mean. More generally, the expected total variational distance for finite-alphabet distributions is a sum of MAD terms.
is the expected total variational distance between the empirical distribution and its mean. More generally, the expected total variational distance for finite-alphabet distributions is a sum of MAD terms. . The first two parts of the lemma are given below.
. The first two parts of the lemma are given below. if and only if
if and only if  and
and  .
. , where
, where  is the unique integer between
is the unique integer between 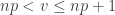 .
. , which implied (to him) that
, which implied (to him) that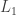 convergence, they call the proof in the
convergence, they call the proof in the 