I updated the poster package that I had written for doing large-format conference posters in LaTeX. The updated package uses PGF and TikZ, which is a way of making beautiful figures in LaTeX. I’ve been using pstricks to make figures for a while, and while it works for me, getting it to work with pdflatex is a pain. Luckily, TikZ works in both the PostScript-based workflow as well as the direct-to-pdf workflow. Many thanks are due to Massimo Canonico for his feedback and comments.
Tag Archives: academia
ISIT : first set of talks
Outer Bounds for User Cooperation
Ravi Tandon, Sennur Ulukus
This paper looked converse bounds for the MAC with generalized feedback. By applying the dependence balance bound, one can get an outer bound for the capacity region in terms of auxiliary random variables whose cardinality is difficult to bound. For a specific form of the channel, the “user cooperation channel.” where the feedback signals to the users are made from noisy versions of the other users’s signal, they find a way to evaluate the bound by looking at all input densities satisfying the constraints and then arguing that it is sufficient to consider Gaussian densities. The resulting bound matches the full-cooperation and no-cooperation bound when taking the respective limits in the feedback noise, and is tighter than the cutset bound.
Optimal Quantization of Random Measurements in Compressed Sensing
John Sun, Vivek Goyal
The goal here was to design a quantizer for noisy measurements in compressed sensing, while keeping the decoder/reconstructor fixed. This was done in the same high rate scalar quantization setting that I’d seen in other talks, with point-density functions to represent the reconstruction points. They draw a connection to the earlier work on functional scalar quantization and find optimal quantizers for the Lasso. They used an recent called “homotopy continuation,” which looks at the solution produced by the Lasso as a function of the regularization parameter, which I should probably read up on a bit more…
A Sparsity Detection Framework for On-Off Random Access Channels
Sundeep Rangan, Alyson Fletcher, Vivek Goyal
This looked at a MAC with 
Eigen-Beamforming with Delayed Feedback and Channel Prediction
Tr Ramya, Srikrishna Bhashyam
This paper looked at the effect of delay in the feedback link in a system that is trying to do beamforming. The main effect of delay is that there is a mismatch between CSIT and CSIR. There is also the effect of channel estimation error. One solution is to do some channel prediction at the encoder, and they show that delayed feedback can affect the diversity order, while prediction can help improve the performance. Unfortunately, at high Doppler shift and and high SNR, the prediction filter becomes too complex. I hadn’t really seen much work on the effect of longer delay in feedback, so this was an interesting set of ideas for me.
ISIT 2009 : post the first
I’m at ISIT 2009 now at the COEX Center. Korea is pretty good so far (pictures to be posted later). The conference started today with a plenary by Rich Baraniuk, who talked about compressed sensing. I’d seen parts of the talk before, but it’s always nice to hear Rich speak because he’s so passionate about how cool the thing is.
I’ll try to blog about talks that I saw that were interesting as time permits — this time I’ll try to reduce the delay between talks and posts!
Academic freedom and speech as public citizens
Michael Bérubé has a nice post on academic freedom up at CT.
Postprint server for the California Digital Library
I’m surprised that there are fewer people using the Postprint server at the California Digital Libary (CDL). This is a service for University of California students, staff, and faculty that lets you post your paper in its final version and makes it freely available. The nice thing is that they pay attention to all the copyright details for you so you don’t have to sort that out. There are a few good reasons to use it : (a) it’s good to archive your work with your “employer,” (b) it helps promote open access to postprints for disciplines which don’t use ArXiV, and (c) they can give you statistics on number of downloads.
Just looking through it seems that a small fraction of the papers written by UC people make it into the repository. The University of California does not have a mandate for open access like Harvard does, but provides this as an option. As Michael Mitzenmacher has noted, mandates can become tricky, which is why the CDL’s managing of the copyright thing is nice.
Students = lemmings?
Apparently students are lemmings:
But a new study by a trio of international researchers finds that college undergraduates let their peers influence their choice of major, often leading them into careers that were not best suited to their skills — and ultimately diminished their income… if the study’s results hold up, students might be encouraged to think for themselves.
The whole thing seems a little suspect to me, and I’m not sure it really generalizes to the US. They studied business students at an Italian university with two choices only (business or economics) and then had a number of group divisions like “ability driven” and “peer driven” to divide them. It just sounds like way too many variables to control for.
However, reading the article reminded me of the game Lemmings, which was awesome in that early 90s way…
Infocom 2009 : capacity of wireless networks
A Theory of QoS for Wireless
I-Hong Hou (University of Illinois at Urbana-Champaign, US); Vivek Borkar (Tata Institute of Fundamental Research, IN); P. R. Kumar (University of Illinois at Urbana-Champaign, US)
This paper claimed to propose a tractable and relevant framework for analyzing the quality of service in a network. In particular, the model should capture deadlines, delivery ratios, and channel reliability while providing guarantees for admission control and scheduling. The model presented was rather simple: there are 


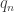
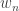
Computing the Capacity Region of a Wireless Network
Ramakrishna Gummadi (University of Illinois at Urbana-Champaign, US); Kyomin Jung (Massachusetts Institute of Technology, US); Devavrat Shah (Massachusetts Institute of Technology, US); Ramavarapu Sreenivas (University of Illinois at Urbana-Champaign, US)
This looked at wireless networks under the protocol model of Gupta and Kumar and asks the following question : if I give you a vector of rates 
The Multicast Capacity Region of Large Wireless Networks
Urs Niesen (Massachusetts Institute of Technology, US); Piyush Gupta (Bell Labs, Alcatel-Lucent, US); Devavrat Shah (Massachusetts Institute of Technology, US)
The network model is ![[0, \sqrt{n}]^2](https://s0.wp.com/latex.php?latex=%5B0%2C+%5Csqrt%7Bn%7D%5D%5E2&bg=ffffff&fg=333333&s=0&c=20201002)

Yet more on Elsevier’s fake journals
But wait… there’s more:
Scientific publishing giant Elsevier put out a total of six publications between 2000 and 2005 that were sponsored by unnamed pharmaceutical companies and looked like peer reviewed medical journals, but did not disclose sponsorship, the company has admitted… Elsevier declined to provide the names of the sponsors of these titles, according to the company spokesperson… last week, Elsevier indicated that it had no plans of looking into the matter further, but that decision has apparently been reversed.
“We are currently conducting an internal review but believe this was an isolated practice from a past period in time,” Hansen continued in the Elsevier statement. “It does not reflect the way we operate today. The individuals involved in the project have long since left the company. I have affirmed our business practices as they relate to what defines a journal and the proper use of disclosure language with our employees to ensure this does not happen again.”
I guess they’re saying “mistakes were made.”
relative price index table
JDO sent me a link to a journal rating databas that tries to calculate a “relative price index” for different journals:
he coloration (red for very low value, yellow for low value, and green for good value) is computed by comparing the composite price index to the median for non-profit journals in the same subject. Be advised that price per citation, price per article and the composite index are not perfect measures of value. Neither of us are experts in most of the fields represented, and others may reasonably, or unreasonably, disagree with the value assessment.
This provides a counterpoint to the impact factor commonly bandied about at academic gatherings. High impact is only one aspect of the cost-effectiveness. For those information theorists out there:
Title: IEEE TRANSACTIONS ON INFORMATION THEORY
Publisher: IEEE-INST ELECTRICAL ELECTRONICS ENGINEERS INC
ISSN: 0018-9448
Subject: Computer Science, Engineering
Profit Status: Non-Profit
Year First Published: 1953
Price per article: 2.43
Price per citation: 1.45
Composite Price Index: 1.88
Relative Price Index 0.24
It’s in the green, which is appropriate, I guess. (Don’t worry, the Transactions on Signal Processing has an RPI of 0.55, so it’s not just judging the journal by its color).
Infocom 2009 : routing
Scalable Routing Via Greedy Embedding
Cedric Westphal (Docomo Labs USA, US); Guanhong Pei (Virginia Tech, US)
In a network, a greedy routing strategy that sends packets to the neighbor closest to the destination may require routing tables of size 
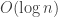


Greedy Routing with Bounded Stretch
Roland Flury (ETH Zurich, Switzerland); Sriram Pemmaraju (The University of Iowa, US); Roger Wattenhofer (ETH Zurich, Switzerland)
This was another talk about greedy routing. If the network has holes in it (imagine a lake) then greedy routing can get stuck because there is no greedy step to take. So there are lots of algorithms out there for recovering when you are stuck. It would be far nicer to get a coordinate system for the graph such that greedy routing always works (in some sense), but so that the stretch is not too bad. This talk proposed a scheme which had three ingredients: spanning trees, separators, and isometric greedy embeddings. Basically the idea (from what I saw in the talk) is to use the existence of separators in the graph to build a tree cover of the graph and then do routing along the best tree in the cover. This guarantees the bounded stretch, and the number of trees needed is not too large, so the labels are not too large either. I think it was a rather nice paper, and between the previous one and this one I was introduced to a new problem I had not thought about before.
Routing Over Multi-hop Wireless Networks with Non-ergodic Mobility
Chris Milling (The University of Texas at Austin, US); Sundar Subramanian (Qualcomm Flarion Technologies, US); Sanjay Shakkottai (The University of Texas at Austin, US); Randall Berry (Northwestern University, US)
In this paper they had a network with some static nodes and some mobile nodes who move in prescribed areas but with no real “model” on their motion. They move arbitrarily according to some arbitrary continuous paths. Some static nodes need to route packets to the mobile nodes. How should they do this? A scheme is proposed in which the static node sends out probe packets to iteratively quarter the network and corral the mobile node. If the mobile crosses a boundary then a node close to the boundary will deliver the packet. An upperbound on the throughput can be shown by considering the mobiles to be at fixed locations (chosen to be the worst possible). This is essentially the worst case, since the rates achieved by their scheme are within a polylog factor of the upper bound. This suggests that the lack of knowledge of the user’s mobility patterns hurts very little in the scaling sense.
