I’ve seen this quote excerpted in parts before, but not the whole thing:
I repeat, feedback is a method for controlling a system by reinserting into it the results of its past performance. If these results are merely used as numerical data for the criticism of the system and its regulation, we have the simple feedback of the control engineers. If, however, the information which proceeds backward from the performance is able to change the general method and pattern of performance, we have a process which may well be called learning.
– Norbert Wiener, The Human Use of Human Beings
It is a strange distinction Wiener is trying to make here. First, Wiener tries to make “numerical data” a simple special case, and equates control as the manipulation of numerical data. However, he doesn’t contrast numbers with something else (presumably non-numerical) which can “change the general method and pattern.” Taking it from the other direction, he implies that mere control engineering cannot accomplish “learning.” That is, from numerical data and “criticism of the system” we cannot change how the system works. By Wiener’s lights, pretty much all of the work in mathematical control and machine learning would be classified as control.
I am, of course, missing the context in which Wiener was writing. But I’m not sure what I’m missing. For example, at the time a “control engineer” may have been more of a regulator, so in the first case Wiener may be referring to putting a human in the loop. In the book he makes a distinction between data and algorithms (the “taping”) which has been fuzzed up by computer science. If this distinction leads to drawing a line between control and learning, then is there a distinction between control and learning?
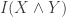 instead of
instead of 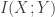 for mutual information, but we can change that in the macro!
for mutual information, but we can change that in the macro! with parameters
with parameters  . Here’s a little follow-up with plots. This is a plot of
. Here’s a little follow-up with plots. This is a plot of  versus
versus  for different values of
for different values of  .
. . Looks beautifully scalloped, no? As we’d expect, the MAD is symmetric about
. Looks beautifully scalloped, no? As we’d expect, the MAD is symmetric about 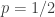 and monotonically increasing for the first half of the unit interval. Unfortunately, it’s clearly not concave (although it is piecewise concave), which means I have to do a bit more algebra later on.
and monotonically increasing for the first half of the unit interval. Unfortunately, it’s clearly not concave (although it is piecewise concave), which means I have to do a bit more algebra later on.


 . So
. So  is the expected total variational distance between the empirical distribution and its mean. More generally, the expected total variational distance for finite-alphabet distributions is a sum of MAD terms.
is the expected total variational distance between the empirical distribution and its mean. More generally, the expected total variational distance for finite-alphabet distributions is a sum of MAD terms.
