I was recently reading a paper on ArXiV that is from the VLDB 2012 conference:
Functional Mechanism: Regression Analysis under Differential Privacy
Jun Zhang, Zhenjie Zhang, Xiaokui Xiao, Yin Yang, Marianne Winslett
The idea of the paper is to make a differentially private approximation to an optimization by perturbing a Taylor series expansion of the objective function. Which is an interesting idea at that. However, what caught my eye was how they referred to an earlier paper of mine (with Kamalika Chaudhuri and Claire Monteleoni) on differentially private empirical risk minimization. What we did in that paper was look at the problem of training classifiers via ERM and the particular examples we used for experiments were logistic regression and SVM.
In the VLDB paper, the authors write:
The algorithm, however, is inapplicable for standard logistic regression, as the cost function of logistic regression does not satisfy convexity requirement. Instead, Chaudhuri et al. demonstrate that their algorithm can address a non-standard type of logistic regression with a modified input (see Section 3 for details). Nevertheless, it is unclear whether the modified logistic regression is useful in practice.
This is just incorrect. What we look at is a fairly standard formulation of logistic regression with labels in {-1,+1}, and do the standard machine learning approach, namely regularized empirical risk minimization. The objective function is, in fact, convex. We further do experiments using that algorithm on standard datasets. Perhaps the empirical performance was not as great as they might like, but then they should make a claim of some sort instead of saying it’s “unclear.”
They further claim:
In particular, they assume that for each tuple t_i, its value on Y is not a boolean value that indicates whether t_i satisfies certain condition; instead, they assume y_i equals the probability that a condition is satisfied given x_i… Furthermore, Chaudhuri et al.’s method cannot be applied on datasets where Y is a boolean attribute…
Firstly, we never make this “assumption.” Secondly, we do experiments using that algorithm on standard datasets where the label is binary. Reading this description was like being in a weird dream-world in which statements are made up and attributed to you.
Naturally, I was a bit confused about this rather blatant misrepresentation of our paper, so I emailed the authors, who essentially said that they were confused by the description in our paper and that more technical definitions are needed because we are from “different communities.” They claimed that they emailed questions about it but we could not find any such emails. Sure, sometimes papers can be confusing if they are out of your area, but to take “I don’t understand X” to “let me make things up about X” requires a level of gumption that I don’t think I could really muster.
In a sense, the publication incentives are stacked in favor of this kind of misrepresentation. VLDB is a very selective conference, so in order to make your contribution seem like a big deal, you have to make it seem that alternative approaches to the problem are severely lacking. However, rather than making a case against the empirical performance of our method, this paper just invented “facts” about our paper. The sad thing is that it seems completely unnecessary, since their method is quite different.
 on a discrete set. The thing is we only have a handle on the entropy
on a discrete set. The thing is we only have a handle on the entropy 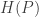 but not on the distribution itself.
but not on the distribution itself. drawn i.i.d. from
drawn i.i.d. from  be the number of distinct symbols in the sample. Then
be the number of distinct symbols in the sample. Then![\mathbb{E}[M] \le \frac{m H(P)}{\log m} + 1](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BM%5D+%5Cle+%5Cfrac%7Bm+H%28P%29%7D%7B%5Clog+m%7D+%2B+1&bg=ffffff&fg=333333&s=0&c=20201002)
 be the probabilities of the different elements. There could be countably many, but we can write the expectation of the number of unique elements as
be the probabilities of the different elements. There could be countably many, but we can write the expectation of the number of unique elements as![\mathbb{E}[M] = \sum_{i=1}^{\infty} (1 - (1 - p_i)^m)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5BM%5D+%3D+%5Csum_%7Bi%3D1%7D%5E%7B%5Cinfty%7D+%281+-+%281+-+p_i%29%5Em%29&bg=ffffff&fg=333333&s=0&c=20201002)
 and consider a sample of size
and consider a sample of size  drawn i.i.d. from
drawn i.i.d. from 
 and
and  and then do the discrete approximate to the gradient. Some of the attendees claimed this is similar to an approach proposed by Nesterov, but the distinction was unclear to me.
and then do the discrete approximate to the gradient. Some of the attendees claimed this is similar to an approach proposed by Nesterov, but the distinction was unclear to me. , where
, where  are your data points and
are your data points and  and does a gradient step at each iteration on
and does a gradient step at each iteration on  . Here what they do at step
. Here what they do at step  is pick a random point
is pick a random point  , evaluate its gradient, but then take a gradient step on all
, evaluate its gradient, but then take a gradient step on all  they just use the gradient from the last time
they just use the gradient from the last time 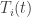 be the last time
be the last time  . Then they take a gradient step like
. Then they take a gradient step like  . This works surprisingly well.
. This works surprisingly well.
