I’m on sabbatical now, which ostensibly means having a bit more time to read things (technical and not). I’m not exactly burning through books but 2019 has already had a few good ones.
Convenience Store Woman (Sayaka Murata): The book has a lot of critical acclaim but I can see many readers being put off by it: the story is pretty disturbing in the end. The narrator and protagonist is (I think) neuro-atypical, which comes across in the writing (I’d love to read some notes from the translator). On the other hand, it is also a critique of Japanese work culture, I think, although not the usual office-drone/salaryman/Aggretsuko type, which is refreshing.
Golden Hill (Francis Spufford): This was a really great picaresque with a lot of detail about early New York that made me want to tour around lower Manhattan with a copy of the manuscript to trace out some of the locations. There’s a twist (as always!) but I don’t want to give it away. Spufford, as usual, has a real ear for the language: although it took a little getting used to, I eventually settled in and it was a real page-turner.
The Ministry of Pain (Dubravka Ugrešić): A novel by a Balkan author living in Amsterdam about a Balkan refugee teaching Balkan literature in Amsterdam to (mostly) other refugees. There’s a lot about language and the war and “our language” as she puts it. The story unfolds slowly but I think the atmosphere and ideas were what I appreciated the most about it. The discomfort of addressing while not reenacting trauma is palpable.
Binti: Home and Binti: The Night Masquerade (Nnedi Okorafor) books 2 and 3 in a sci-fi trilogy. The world expands quite a bit beyond the first one and I thought Binti’s character arc was quite dramatic. I wish there had been more to learn about the other characters as well. But these books are novellas so perhaps I should do a bit more work to fill in the gaps with my imagination?
Stranger in a Strange Land: Searching for Gershom Scholem and Jerusalem (George Prochnik): A rather discursive biography of Gershom Scholem, who almost single-handedly (it seems) made started the academic study of Kabbalah which is interleaved with the author’s autobiography of moving to Jerusalem, taking up graduate studies, starting a family, and becoming disenchanted. I thought it was a stretch at times to relate the two, and I had no prior information about Scholem but I found myself almost wanting two books: a straight biography and a straight memoir. Both had their merits but the alternation made it a bit of a slog to read.
 -sided die with numbers
-sided die with numbers 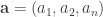 and call
and call  the face sum. The die is fair, so the expected face value is
the face sum. The die is fair, so the expected face value is  . We can define an ordering on dice by saying $\mathbf{a} \succ \mathbf{b}$ if a uniformly chosen face of
. We can define an ordering on dice by saying $\mathbf{a} \succ \mathbf{b}$ if a uniformly chosen face of 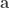 is larger than a uniformly chosen face of
is larger than a uniformly chosen face of 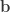 . That is, if you roll both dice then on average
. That is, if you roll both dice then on average 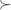 based on dice beating each other cannot be extended to a linear order. The connection to elections is in ranked voting — an election in which voters rank candidates may exhibit a
based on dice beating each other cannot be extended to a linear order. The connection to elections is in ranked voting — an election in which voters rank candidates may exhibit a ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) and condition on the face sum being equal to
and condition on the face sum being equal to  . Then as the number of faces
. Then as the number of faces 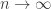 , three such independently generated dice will become intransitive with high probability (see the
, three such independently generated dice will become intransitive with high probability (see the 