A while back I heard this NPR story about a method for predicting attacks that was published in Science. The news story left me a bit perplexed — where was the prediction? It turns out to be yet another version of attack of the power laws. After a bit of curve fitting, the meat of the thing seems to be this:
Our broad-brush theory does not require knowledge of specific adaptation or counteradaptation mechanisms, and hence bypasses issues such as changes in insurgent membership, technology, learning, or skill set, as well as a need to know the hearts and minds of local residents. We regard the escalation of hostilities as representing adaptation and counteradaptation in a way that is analogous to the Red Queen hypothesis of evolutionary biology. (Johnson et al. 2011)
Hearts and minds : pish-posh, what nonsense. Bring on the Red Queen!
This continual arms race of adaptation and counter-adaptation suggests similarities with Darwinian selection in nature. As noted by Rafe Sagarin, “a fundamental tenet of evolutionary biology is that organisms must constantly adapt just to stay in the same strategic position relative to their enemies—who are constantly changing as well. For example, to protect its DNA against viruses, a host organism must continually change the access code to its genetic material” (Sagarin, 2003, p. 69). Meeting the Red Queen in Alice in Wonderland, Alice finds that however fast she runs, she always stays in the same place. The “Red Queen” concept has become widely used in evolutionary biology to describe how competing individuals can become locked in an “arms race” of strategies, machinery, or weapons. However impressive one side becomes, it may never come any closer to defeating its opponent. (Johnson 2009)
Unfortunately, Red-Queen like equilibrium is not possible. Since they’ve already thrown out the idea of modeling, they’re left with fitting parameters in a stochastic model:
However, instantaneous and perfect counteradaptation is unrealistic; indeed, complex adaptation-counteradaptation dynamics generated by sporadic changes in circumstances imply that R’s temporal evolution is likely to be so complex that it can be modeled as a stochastic process. We do not need to know exactly why changes at any specific moment, nor do the changes in have to have the same value, because each change is the net result of a mix of factors [such as learning by experience or changes in personnel and technology] for each opponent. (Johnson et al. 2011)
They they go on to say that once you fit the parameters you could estimate momentum from a few fatal days to estimate the timing of the next fatal day. But they don’t actually do this (say, by holding out some data and doing a little validation), except an example of a single prediction being more accurate than one might expect.
So in the end, what do we have? This is a paper about modeling and not about prediction, but prediction sounds a lot more sexy, and so NPR ran with that aspect of it. In order to build a predictor, you would need to build a good model, which presumably means sitting around and waiting for fatal attacks to happen because you can’t make an omelette predictive model without breaking some eggs killing some people. Finally, “ZOMG P0W3R L4WZ” is so the aughts.
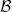 has Martingale-type
has Martingale-type  (or M-type
(or M-type  such that for any
such that for any  and
and  , we have
, we have ![\displaystyle \sup_{t} \mathop{\mathbb E}\left[ \left\| Y_t \right\| \right] \le C \left( \sum_{t=1}^{\infty} \mathop{\mathbb E}[ \left\| Y_t - Y_{t-1} \right\| ^p ] \right)^{1/p}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09%5Csup_%7Bt%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cleft%5C%7C+Y_t+%5Cright%5C%7C+%5Cright%5D+%5Cle+C+%5Cleft%28+%5Csum_%7Bt%3D1%7D%5E%7B%5Cinfty%7D+%5Cmathop%7B%5Cmathbb+E%7D%5B+%5Cleft%5C%7C+Y_t+-+Y_%7Bt-1%7D+%5Cright%5C%7C+%5Ep+%5D+%5Cright%29%5E%7B1%2Fp%7D.+%09&bg=ffffff&fg=000000&s=0&c=20201002)
 (or M-cotype
(or M-cotype ![\displaystyle \left( \sum_{t=1}^{\infty} \mathop{\mathbb E}[ \left\| Y_t - Y_{t-1} \right\|^q ] \right)^{1/q} \le C \sup_{t} \mathop{\mathbb E}\left[ \left\| Y_t \right\| \right].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%09+%5Cleft%28+%5Csum_%7Bt%3D1%7D%5E%7B%5Cinfty%7D+%5Cmathop%7B%5Cmathbb+E%7D%5B+%5Cleft%5C%7C+Y_t+-+Y_%7Bt-1%7D+%5Cright%5C%7C%5Eq+%5D+%5Cright%29%5E%7B1%2Fq%7D+%09+%5Cle+%09+C+%5Csup_%7Bt%7D+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cleft%5C%7C+Y_t+%5Cright%5C%7C+%5Cright%5D.+%09&bg=ffffff&fg=000000&s=0&c=20201002)
 kind of stuff, but how does this relate to overall geometric properties of the space?
kind of stuff, but how does this relate to overall geometric properties of the space?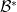 is reflexive. A space
is reflexive. A space 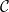 is finitely representable in
is finitely representable in  and any
and any  there exists an isomorphism
there exists an isomorphism  such that
such that 
 there exists a
there exists a 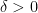 such that for two unit vectors
such that for two unit vectors  and
and  ,
, 

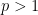 the spaces
the spaces 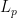 and
and  are uniformly convex. Another way to picture it is that if the midpoint of the chord between
are uniformly convex. Another way to picture it is that if the midpoint of the chord between 
 ). Furthermore, a Banach space has M-cotype
). Furthermore, a Banach space has M-cotype 