The IEEE Transactions on Information Theory recently transitioned to using Manuscript Central from the old Pareja system, so now all of the IEEE journals for which I review seem to be managed by the same external management system. As a reviewer/author, I have a lot of complaints (small and large) about Manuscript Central:
- Why oh why do I need to disable my popup blocker for your site to work?
- Why can login information not be shared across different IEEE publications? I have a separate account for each journal, with a separate password. Thank goodness I have LastPass, but even that program gets confused sometimes.
- What is the deal with the mandatory subject classifications for papers? One of the “topics” I could pick was “IEEE Transactions on Information Theory.” Really? That’s a topic?
- Why must papers for review be emblazoned with that stupid pale blue “For Peer Review Only” running diagonally across each page? This causes PDF annotations such as highlighting to barf, making paperless reviewing of papers significantly more annoying than it needs to be.
The worst part is that I am sure IEEE could implement a significantly cheaper and just-as-effective system itself, but now each Society is forking over money to Manuscript Central, which as far as I can tell, offers significantly more annoyances for authors and reviewers and is a shoddy product. Perhaps as an editor it’s significantly better (I imagine it is), but it seems like a bad deal overall.
Of course, now I sound curmudgeonly. Get off my lawn!
Do other people like MC? Or do you have other pet peeves?
 of coming up heads. You can flip the coin as many times as you like (or more precisely, you can flip the coin an infinite number of times). Let
of coming up heads. You can flip the coin as many times as you like (or more precisely, you can flip the coin an infinite number of times). Let 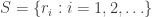 be the set of rational numbers in
be the set of rational numbers in ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . After each flip, you have to guess one of the following hypotheses: that
. After each flip, you have to guess one of the following hypotheses: that  for a particular
for a particular  , or
, or ![p \in [0,1] - N_0](https://s0.wp.com/latex.php?latex=p+%5Cin+%5B0%2C1%5D+-+N_0&bg=ffffff&fg=333333&s=0&c=20201002) , where
, where 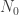 is a set of irrationals of Lebesgue measure 0. Can you do it? If so, how?
is a set of irrationals of Lebesgue measure 0. Can you do it? If so, how? you have a function
you have a function 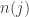 . Think of
. Think of 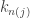 , and an interval width
, and an interval width  .
. 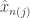 and look at a interval of width
and look at a interval of width 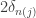 centered on it. Note that this makes the same decision for each
centered on it. Note that this makes the same decision for each  until
until  , find the smallest
, find the smallest ![r_i \in [\hat{x} - \delta_{n(j)}, \hat{x} + \delta_{n(j)}]](https://s0.wp.com/latex.php?latex=r_i+%5Cin+%5B%5Chat%7Bx%7D+-+%5Cdelta_%7Bn%28j%29%7D%2C+%5Chat%7Bx%7D+%2B+%5Cdelta_%7Bn%28j%29%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
.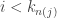 such that
such that 
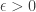 ,
,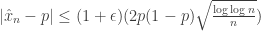
 . This gets used to set the interval width
. This gets used to set the interval width 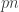 total bit flips. That is, Calvin is causal : the decision to flip bit
total bit flips. That is, Calvin is causal : the decision to flip bit  . What we show is a new upper bound on the capacity of this channel. Let
. What we show is a new upper bound on the capacity of this channel. Let 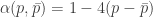 . Then
. Then![C \le \min_{\bar{p} \in [0,p]} \left[ \alpha(p,\bar{p})\left(1-H\left(\frac{\bar{p}}{\alpha(p,\bar{p})}\right)\right) \right]](https://s0.wp.com/latex.php?latex=C+%5Cle+%5Cmin_%7B%5Cbar%7Bp%7D+%5Cin+%5B0%2Cp%5D%7D+%5Cleft%5B+%5Calpha%28p%2C%5Cbar%7Bp%7D%29%5Cleft%281-H%5Cleft%28%5Cfrac%7B%5Cbar%7Bp%7D%7D%7B%5Calpha%28p%2C%5Cbar%7Bp%7D%29%7D%5Cright%29%5Cright%29+%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)

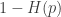 bound).
bound).
 channel uses and the second of length
channel uses and the second of length  . Let
. Let 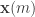 be the codeword for message
be the codeword for message  .
. indices uniformly from all
indices uniformly from all 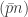 -subsets of
-subsets of 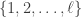 and flips bit
and flips bit 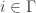 .
.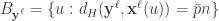 ,
, uniformly at random. For the second phase, Calvin selectively pushes the received codeword towards
uniformly at random. For the second phase, Calvin selectively pushes the received codeword towards  — if the transmitted codeword and the selected codeword match, he does nothing, and if they do not match he flips the bit with probability
— if the transmitted codeword and the selected codeword match, he does nothing, and if they do not match he flips the bit with probability  .
. and Calvin chose
and Calvin chose  is the same as the chance Alice chose
is the same as the chance Alice chose  . To establish this symmetry condition requires some technical excursions which are less fun to blog about, but were fun to figure out.
. To establish this symmetry condition requires some technical excursions which are less fun to blog about, but were fun to figure out. data matrix
data matrix  into a form acceptable for statistical or machine learning algorithms that assume things like zero-mean or bounded vectors. Here
into a form acceptable for statistical or machine learning algorithms that assume things like zero-mean or bounded vectors. Here  the number of features, for example. Or the data may come from a DNA microarray (their motivating example). This preprocessing is often done without much theoretical justification — the mathematical equivalence of tossing spilled salt over your shoulder. This paper looks at the limiting process of standardizing rows and then columns and then rows and then columns again and again. They further need that
the number of features, for example. Or the data may come from a DNA microarray (their motivating example). This preprocessing is often done without much theoretical justification — the mathematical equivalence of tossing spilled salt over your shoulder. This paper looks at the limiting process of standardizing rows and then columns and then rows and then columns again and again. They further need that 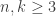 . “Readers will see that the process and perhaps especially the mathematics that underlies it are not as simple as we had hoped they would be.”
. “Readers will see that the process and perhaps especially the mathematics that underlies it are not as simple as we had hoped they would be.”