It’s the fall again, and this year it is the 50th anniversary of the Allerton Conference. Tonight was a special Golden Jubilee lecture by Karl Johan Åström from the Lund University. He gave an engaging view of the pre-history, history, present, and future of control systems. Control is a “hidden technology” he said — it’s everywhere and is what makes all the technology that we use work, but remains largely unknown and unnoticed except during catastrophic failures. He exhorted the young’uns to do a better job at letting people know how important control systems are in everyday life.
The main message of Åström’s talk is that control theory and control practice need to get back together so that we can develop new control theories for emerging areas, including biology and physics. He called this the “holistic” view and pointed out that it really emerged out of the war effort during WWII, when control systems had to be developed for all sorts of military tasks. This got the mathematicians in the same room as the “real” engineers, and led to a lot of new theory. I guess I had always known that was a big driver, but I guess I hadn’t thought of how control really was the glue that tied things together.

 and
and 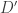 , we want to analyze the behavior of the random variable
, we want to analyze the behavior of the random variable  for measurable sets
for measurable sets  .
. 
 ?
?